Testirajte AI na VAŠI spletni strani v 60 sekundah
Poglejte, kako naša umetna inteligenca takoj analizira vašo spletno stran in ustvari personaliziranega chatbota - brez registracije. Samo vnesite svoj URL in opazujte, kako deluje!
Pripravljeno v 60 sekundah
Brez potrebe po kodiranju
100% varno
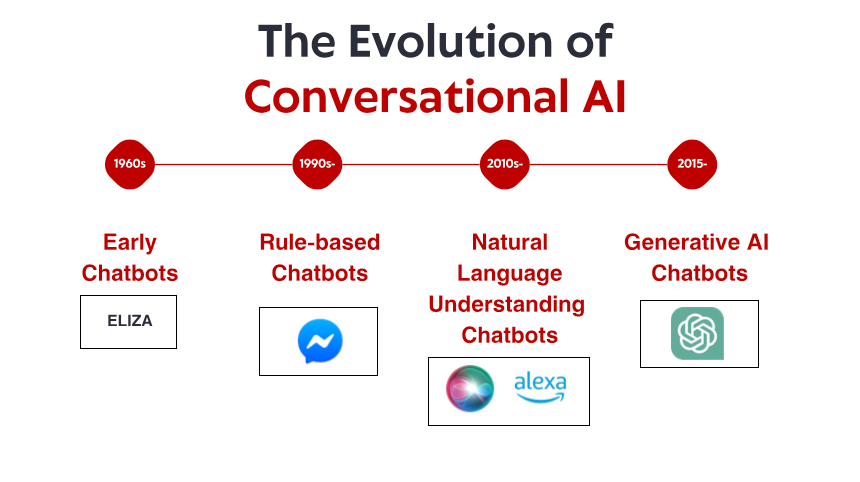
Skromni začetki: Zgodnji sistemi, ki temeljijo na pravilih
Zgodba pogovorne umetne inteligence se začne v šestdesetih letih prejšnjega stoletja, dolgo preden so pametni telefoni in glasovni pomočniki postali stalnica gospodinjstva. V majhnem laboratoriju na MIT je računalniški znanstvenik Joseph Weizenbaum ustvaril tisto, kar mnogi smatrajo za prvega chatbota: ELIZA. ELIZA je bila zasnovana za simulacijo Rogerianskega psihoterapevta in je delala s preprostimi pravili ujemanja vzorcev in zamenjave. Ko uporabnik vtipka »Žalostna sem«, lahko ELIZA odgovori z »Zakaj si žalosten?« – ustvarjanje iluzije razumevanja s preoblikovanje izjav v vprašanja.
Kar je naredilo ELIZO izjemno, ni bila njena tehnična dovršenost – po današnjih standardih je bil program neverjetno preprost. Namesto tega je šlo za močan učinek na uporabnike. Kljub temu, da so vedeli, da se pogovarjajo z računalniškim programom brez dejanskega razumevanja, je veliko ljudi vzpostavilo čustveno povezavo z ELIZO ter delilo globoko osebne misli in občutke. Ta pojav, ki se je sam Weizenbaum zdel moteč, je razkril nekaj temeljnega o človeški psihologiji in naši pripravljenosti, da antropomorfiziramo celo najpreprostejše pogovorne vmesnike.
V sedemdesetih in osemdesetih letih prejšnjega stoletja so klepetalni roboti, ki temeljijo na pravilih, sledili predlogi ELIZA s postopnimi izboljšavami. Programa, kot sta PARRY (simulira paranoičnega shizofrenika) in RACTER (ki je "avtor" knjige z naslovom "Policistova brada je napol zgrajena"), sta ostala trdno znotraj paradigme, ki temelji na pravilih – z uporabo vnaprej določenih vzorcev, ujemanja ključnih besed in odzivov v obliki predlog.
Ti zgodnji sistemi so imeli resne omejitve. Dejansko niso mogli razumeti jezika, se učiti iz interakcij ali prilagoditi nepričakovanim vnosom. Njihovo znanje je bilo omejeno na vsa pravila, ki so jih njihovi programerji izrecno definirali. Ko so uporabniki neizogibno zašli izven teh meja, se je iluzija inteligence hitro razblinila in razkrila mehanično naravo pod njo. Kljub tem omejitvam so ti pionirski sistemi postavili osnovo, na kateri bo zgrajena vsa prihodnja pogovorna umetna inteligenca.
Kar je naredilo ELIZO izjemno, ni bila njena tehnična dovršenost – po današnjih standardih je bil program neverjetno preprost. Namesto tega je šlo za močan učinek na uporabnike. Kljub temu, da so vedeli, da se pogovarjajo z računalniškim programom brez dejanskega razumevanja, je veliko ljudi vzpostavilo čustveno povezavo z ELIZO ter delilo globoko osebne misli in občutke. Ta pojav, ki se je sam Weizenbaum zdel moteč, je razkril nekaj temeljnega o človeški psihologiji in naši pripravljenosti, da antropomorfiziramo celo najpreprostejše pogovorne vmesnike.
V sedemdesetih in osemdesetih letih prejšnjega stoletja so klepetalni roboti, ki temeljijo na pravilih, sledili predlogi ELIZA s postopnimi izboljšavami. Programa, kot sta PARRY (simulira paranoičnega shizofrenika) in RACTER (ki je "avtor" knjige z naslovom "Policistova brada je napol zgrajena"), sta ostala trdno znotraj paradigme, ki temelji na pravilih – z uporabo vnaprej določenih vzorcev, ujemanja ključnih besed in odzivov v obliki predlog.
Ti zgodnji sistemi so imeli resne omejitve. Dejansko niso mogli razumeti jezika, se učiti iz interakcij ali prilagoditi nepričakovanim vnosom. Njihovo znanje je bilo omejeno na vsa pravila, ki so jih njihovi programerji izrecno definirali. Ko so uporabniki neizogibno zašli izven teh meja, se je iluzija inteligence hitro razblinila in razkrila mehanično naravo pod njo. Kljub tem omejitvam so ti pionirski sistemi postavili osnovo, na kateri bo zgrajena vsa prihodnja pogovorna umetna inteligenca.
Revolucija znanja: ekspertni sistemi in strukturirane informacije
V osemdesetih in zgodnjih devetdesetih letih prejšnjega stoletja so se pojavili ekspertni sistemi – programi umetne inteligence, zasnovani za reševanje zapletenih problemov s posnemanjem sposobnosti odločanja človeških strokovnjakov na določenih področjih. Čeprav niso bili zasnovani predvsem za pogovor, so ti sistemi predstavljali pomemben evolucijski korak za pogovorno umetno inteligenco z uvedbo bolj izpopolnjene predstavitve znanja.
Strokovni sistemi, kot sta MYCIN (ki je diagnosticiral bakterijske okužbe) in DENDRAL (ki je identificiral kemične spojine), so organizirali informacije v strukturiranih bazah znanja in uporabili mehanizme sklepanja za sklepanje. Ko se uporablja za pogovorne vmesnike, je ta pristop omogočil klepetalnim robotom, da presežejo preprosto ujemanje vzorcev k nečemu, kar je podobno razmišljanju – vsaj znotraj ozkih domen.
Podjetja so začela izvajati praktične aplikacije, kot so avtomatizirani sistemi za pomoč strankam, ki uporabljajo to tehnologijo. Ti sistemi so običajno uporabljali odločitvena drevesa in interakcije na podlagi menija namesto pogovora v prosti obliki, vendar so predstavljali zgodnje poskuse avtomatizacije interakcij, ki so prej zahtevale človeško posredovanje.
Omejitve so ostale pomembne. Ti sistemi so bili krhki in niso mogli elegantno obravnavati nepričakovanih vnosov. Od inženirjev znanja so zahtevali ogromno truda za ročno kodiranje informacij in pravil. In kar je morda najpomembnejše, še vedno niso mogli zares razumeti naravnega jezika v njegovi polni kompleksnosti in dvoumnosti.
Kljub temu je to obdobje vzpostavilo pomembne koncepte, ki bodo kasneje postali ključni za sodobno pogovorno umetno inteligenco: strukturirano predstavitev znanja, logično sklepanje in specializacija področja. Pripravljalo se je oder za spremembo paradigme, čeprav tehnologija še ni bila povsem tam.
Strokovni sistemi, kot sta MYCIN (ki je diagnosticiral bakterijske okužbe) in DENDRAL (ki je identificiral kemične spojine), so organizirali informacije v strukturiranih bazah znanja in uporabili mehanizme sklepanja za sklepanje. Ko se uporablja za pogovorne vmesnike, je ta pristop omogočil klepetalnim robotom, da presežejo preprosto ujemanje vzorcev k nečemu, kar je podobno razmišljanju – vsaj znotraj ozkih domen.
Podjetja so začela izvajati praktične aplikacije, kot so avtomatizirani sistemi za pomoč strankam, ki uporabljajo to tehnologijo. Ti sistemi so običajno uporabljali odločitvena drevesa in interakcije na podlagi menija namesto pogovora v prosti obliki, vendar so predstavljali zgodnje poskuse avtomatizacije interakcij, ki so prej zahtevale človeško posredovanje.
Omejitve so ostale pomembne. Ti sistemi so bili krhki in niso mogli elegantno obravnavati nepričakovanih vnosov. Od inženirjev znanja so zahtevali ogromno truda za ročno kodiranje informacij in pravil. In kar je morda najpomembnejše, še vedno niso mogli zares razumeti naravnega jezika v njegovi polni kompleksnosti in dvoumnosti.
Kljub temu je to obdobje vzpostavilo pomembne koncepte, ki bodo kasneje postali ključni za sodobno pogovorno umetno inteligenco: strukturirano predstavitev znanja, logično sklepanje in specializacija področja. Pripravljalo se je oder za spremembo paradigme, čeprav tehnologija še ni bila povsem tam.
Razumevanje naravnega jezika: Preboj v računalniški lingvistiki
Konec 1990-ih in začetek 2000-ih so prinesli vse večji poudarek na obdelavi naravnega jezika (NLP) in računalniškem jezikoslovju. Namesto da bi poskušali ročno kodirati pravila za vsako možno interakcijo, so raziskovalci začeli razvijati statistične metode, ki bi računalnikom pomagale razumeti inherentne vzorce v človeškem jeziku.
Ta premik je omogočilo več dejavnikov: večja računalniška moč, boljši algoritmi in, kar je bistveno, razpoložljivost velikih besedilnih korpusov, ki jih je bilo mogoče analizirati za prepoznavanje jezikovnih vzorcev. Sistemi so začeli vključevati tehnike, kot so:
Označevanje dela govora: ugotavljanje, ali so besede delovale kot samostalniki, glagoli, pridevniki itd.
Prepoznavanje poimenovanih entitet: zaznavanje in razvrščanje lastnih imen (ljudi, organizacij, lokacij).
Sentiment analiza: Določanje čustvenega tona besedila.
Razčlenjevanje: Analiza strukture stavka za prepoznavanje slovničnih odnosov med besedami.
Eden pomembnih prebojev je prišel z IBM-ovim Watsonom, ki je slavno premagal človeške prvake v kvizu Jeopardy! leta 2011. Čeprav Watson ni bil izključno pogovorni sistem, je pokazal izjemne sposobnosti razumevanja vprašanj v naravnem jeziku, iskanja po obsežnih skladiščih znanja in oblikovanja odgovorov – zmožnosti, ki bi se izkazale za bistvene za naslednjo generacijo klepetalnih robotov.
Kmalu so sledile komercialne aplikacije. Applov Siri je bil predstavljen leta 2011 in prinaša pogovorne vmesnike običajnim uporabnikom. Čeprav je Siri omejena z današnjimi standardi, je predstavljala pomemben napredek pri zagotavljanju dostopnosti pomočnikov AI vsakodnevnim uporabnikom. Sledile bi Microsoftova Cortana, Googlov pomočnik in Amazonova Alexa, ki bi vsak od njih spodbujal napredek na področju konverzacijske umetne inteligence, namenjene potrošnikom.
Kljub temu napredku so se sistemi iz te dobe še vedno borili s kontekstom, zdravorazumskim razmišljanjem in ustvarjanjem resnično naravno zvenečih odzivov. Bili so bolj sofisticirani od svojih prednikov, ki so temeljili na pravilih, vendar so ostali bistveno omejeni v razumevanju jezika in sveta.
Ta premik je omogočilo več dejavnikov: večja računalniška moč, boljši algoritmi in, kar je bistveno, razpoložljivost velikih besedilnih korpusov, ki jih je bilo mogoče analizirati za prepoznavanje jezikovnih vzorcev. Sistemi so začeli vključevati tehnike, kot so:
Označevanje dela govora: ugotavljanje, ali so besede delovale kot samostalniki, glagoli, pridevniki itd.
Prepoznavanje poimenovanih entitet: zaznavanje in razvrščanje lastnih imen (ljudi, organizacij, lokacij).
Sentiment analiza: Določanje čustvenega tona besedila.
Razčlenjevanje: Analiza strukture stavka za prepoznavanje slovničnih odnosov med besedami.
Eden pomembnih prebojev je prišel z IBM-ovim Watsonom, ki je slavno premagal človeške prvake v kvizu Jeopardy! leta 2011. Čeprav Watson ni bil izključno pogovorni sistem, je pokazal izjemne sposobnosti razumevanja vprašanj v naravnem jeziku, iskanja po obsežnih skladiščih znanja in oblikovanja odgovorov – zmožnosti, ki bi se izkazale za bistvene za naslednjo generacijo klepetalnih robotov.
Kmalu so sledile komercialne aplikacije. Applov Siri je bil predstavljen leta 2011 in prinaša pogovorne vmesnike običajnim uporabnikom. Čeprav je Siri omejena z današnjimi standardi, je predstavljala pomemben napredek pri zagotavljanju dostopnosti pomočnikov AI vsakodnevnim uporabnikom. Sledile bi Microsoftova Cortana, Googlov pomočnik in Amazonova Alexa, ki bi vsak od njih spodbujal napredek na področju konverzacijske umetne inteligence, namenjene potrošnikom.
Kljub temu napredku so se sistemi iz te dobe še vedno borili s kontekstom, zdravorazumskim razmišljanjem in ustvarjanjem resnično naravno zvenečih odzivov. Bili so bolj sofisticirani od svojih prednikov, ki so temeljili na pravilih, vendar so ostali bistveno omejeni v razumevanju jezika in sveta.
Strojno učenje in pristop, ki temelji na podatkih
Sredina 2010-ih je zaznamovala še eno spremembo paradigme pogovorne umetne inteligence z glavnim sprejetjem tehnik strojnega učenja. Namesto da bi se zanašali na ročno izdelana pravila ali omejene statistične modele, so inženirji začeli graditi sisteme, ki bi se lahko učili vzorcev neposredno iz podatkov – in to veliko.
V tem obdobju je prišlo do vzpona klasifikacije namenov in ekstrakcije entitet kot ključnih komponent pogovorne arhitekture. Ko je uporabnik podal zahtevo, bi sistem:
Razvrstite splošni namen (npr. rezervacija leta, preverjanje vremena, predvajanje glasbe)
Izvleček ustreznih entitet (npr. lokacije, datumi, naslovi pesmi)
Preslikajte jih v določena dejanja ali odzive
Facebookova (zdaj Meta) uvedba svoje platforme Messenger leta 2016 je razvijalcem omogočila ustvarjanje chatbotov, ki bi lahko dosegli milijone uporabnikov, kar je sprožilo val komercialnega zanimanja. Mnoga podjetja so pohitela z uvedbo chatbotov, čeprav so bili rezultati mešani. Zgodnje komercialne izvedbe so uporabnike pogosto razočarale zaradi omejenega razumevanja in togih tokov pogovorov.
V tem obdobju se je razvila tudi tehnična arhitektura pogovornih sistemov. Tipičen pristop je vključeval cevovod specializiranih komponent:
Samodejno prepoznavanje govora (za glasovne vmesnike)
Razumevanje naravnega jezika
Upravljanje dialoga
Generacija naravnega jezika
Pretvorba besedila v govor (za glasovne vmesnike)
Vsako komponento je mogoče optimizirati ločeno, kar omogoča postopne izboljšave. Vendar so te arhitekture cevovodov včasih trpele zaradi širjenja napak – napake v zgodnjih fazah so se kaskadno širile po sistemu.
Medtem ko je strojno učenje znatno izboljšalo zmogljivosti, so sistemi še vedno imeli težave z ohranjanjem konteksta v dolgih pogovorih, razumevanjem implicitnih informacij in ustvarjanjem resnično raznolikih in naravnih odzivov. Naslednji preboj bi zahteval bolj radikalen pristop.
V tem obdobju je prišlo do vzpona klasifikacije namenov in ekstrakcije entitet kot ključnih komponent pogovorne arhitekture. Ko je uporabnik podal zahtevo, bi sistem:
Razvrstite splošni namen (npr. rezervacija leta, preverjanje vremena, predvajanje glasbe)
Izvleček ustreznih entitet (npr. lokacije, datumi, naslovi pesmi)
Preslikajte jih v določena dejanja ali odzive
Facebookova (zdaj Meta) uvedba svoje platforme Messenger leta 2016 je razvijalcem omogočila ustvarjanje chatbotov, ki bi lahko dosegli milijone uporabnikov, kar je sprožilo val komercialnega zanimanja. Mnoga podjetja so pohitela z uvedbo chatbotov, čeprav so bili rezultati mešani. Zgodnje komercialne izvedbe so uporabnike pogosto razočarale zaradi omejenega razumevanja in togih tokov pogovorov.
V tem obdobju se je razvila tudi tehnična arhitektura pogovornih sistemov. Tipičen pristop je vključeval cevovod specializiranih komponent:
Samodejno prepoznavanje govora (za glasovne vmesnike)
Razumevanje naravnega jezika
Upravljanje dialoga
Generacija naravnega jezika
Pretvorba besedila v govor (za glasovne vmesnike)
Vsako komponento je mogoče optimizirati ločeno, kar omogoča postopne izboljšave. Vendar so te arhitekture cevovodov včasih trpele zaradi širjenja napak – napake v zgodnjih fazah so se kaskadno širile po sistemu.
Medtem ko je strojno učenje znatno izboljšalo zmogljivosti, so sistemi še vedno imeli težave z ohranjanjem konteksta v dolgih pogovorih, razumevanjem implicitnih informacij in ustvarjanjem resnično raznolikih in naravnih odzivov. Naslednji preboj bi zahteval bolj radikalen pristop.
Transformerjeva revolucija: nevronski jezikovni modeli
Leto 2017 je zaznamovalo prelomni trenutek v zgodovini umetne inteligence z objavo knjige »Attention Is All You Need«, ki je predstavila arhitekturo Transformer, ki bo spremenila procesiranje naravnega jezika. Za razliko od prejšnjih pristopov, ki so besedilo obdelovali zaporedno, so lahko Transformerji hkrati obravnavali celoten odlomek, kar jim je omogočilo, da bolje zajamejo razmerja med besedami ne glede na njihovo medsebojno razdaljo.
Ta inovacija je omogočila razvoj vedno močnejših jezikovnih modelov. Leta 2018 je Google predstavil BERT (dvosmerne kodirne predstavitve iz transformatorjev), ki je dramatično izboljšal zmogljivost pri različnih nalogah razumevanja jezika. Leta 2019 je OpenAI izdal GPT-2, ki je pokazal zmožnosti brez primere pri ustvarjanju skladnega, kontekstualno ustreznega besedila.
Najbolj dramatičen preskok je bil leta 2020 z GPT-3, ki je povečal na 175 milijard parametrov (v primerjavi z 1,5 milijarde GPT-2). To ogromno povečanje obsega je v kombinaciji z arhitekturnimi izboljšavami ustvarilo kvalitativno drugačne zmogljivosti. GPT-3 je lahko ustvaril neverjetno človeško besedilo, razumel kontekst v tisočih besedah in celo izvajal naloge, za katere ni bil izrecno usposobljen.
Za pogovorni AI se je ta napredek prevedel v chatbote, ki bi lahko:
Ohranjajte koherentne pogovore v več obratih
Razumevanje niansiranih poizvedb brez izrecnega usposabljanja
Ustvarite raznolike, kontekstualno ustrezne odgovore
Prilagodite njihov ton in slog uporabniku
Obravnavajte dvoumnost in po potrebi pojasnite
Izdaja ChatGPT konec leta 2022 je te zmogljivosti prinesla v mainstream in pritegnila več kot milijon uporabnikov v nekaj dneh po uvedbi. Nenadoma je širša javnost imela dostop do pogovorne umetne inteligence, ki se je zdela kvalitativno drugačna od vsega, kar je bilo prej – bolj prilagodljiva, z več znanja in bolj naravna v svojih interakcijah.
Hitro so sledile komercialne implementacije, pri čemer so podjetja vključila velike jezikovne modele v svoje platforme za pomoč strankam, orodja za ustvarjanje vsebine in aplikacije za produktivnost. Hitro sprejemanje je odraz tako tehnološkega preskoka kot intuitivnega vmesnika, ki so ga zagotavljali ti modeli – pogovor je navsezadnje najbolj naraven način za človeško komunikacijo.
Ta inovacija je omogočila razvoj vedno močnejših jezikovnih modelov. Leta 2018 je Google predstavil BERT (dvosmerne kodirne predstavitve iz transformatorjev), ki je dramatično izboljšal zmogljivost pri različnih nalogah razumevanja jezika. Leta 2019 je OpenAI izdal GPT-2, ki je pokazal zmožnosti brez primere pri ustvarjanju skladnega, kontekstualno ustreznega besedila.
Najbolj dramatičen preskok je bil leta 2020 z GPT-3, ki je povečal na 175 milijard parametrov (v primerjavi z 1,5 milijarde GPT-2). To ogromno povečanje obsega je v kombinaciji z arhitekturnimi izboljšavami ustvarilo kvalitativno drugačne zmogljivosti. GPT-3 je lahko ustvaril neverjetno človeško besedilo, razumel kontekst v tisočih besedah in celo izvajal naloge, za katere ni bil izrecno usposobljen.
Za pogovorni AI se je ta napredek prevedel v chatbote, ki bi lahko:
Ohranjajte koherentne pogovore v več obratih
Razumevanje niansiranih poizvedb brez izrecnega usposabljanja
Ustvarite raznolike, kontekstualno ustrezne odgovore
Prilagodite njihov ton in slog uporabniku
Obravnavajte dvoumnost in po potrebi pojasnite
Izdaja ChatGPT konec leta 2022 je te zmogljivosti prinesla v mainstream in pritegnila več kot milijon uporabnikov v nekaj dneh po uvedbi. Nenadoma je širša javnost imela dostop do pogovorne umetne inteligence, ki se je zdela kvalitativno drugačna od vsega, kar je bilo prej – bolj prilagodljiva, z več znanja in bolj naravna v svojih interakcijah.
Hitro so sledile komercialne implementacije, pri čemer so podjetja vključila velike jezikovne modele v svoje platforme za pomoč strankam, orodja za ustvarjanje vsebine in aplikacije za produktivnost. Hitro sprejemanje je odraz tako tehnološkega preskoka kot intuitivnega vmesnika, ki so ga zagotavljali ti modeli – pogovor je navsezadnje najbolj naraven način za človeško komunikacijo.
Testirajte AI na VAŠI spletni strani v 60 sekundah
Poglejte, kako naša umetna inteligenca takoj analizira vašo spletno stran in ustvari personaliziranega chatbota - brez registracije. Samo vnesite svoj URL in opazujte, kako deluje!
Pripravljeno v 60 sekundah
Brez potrebe po kodiranju
100% varno
Multimodalne zmogljivosti: več kot samo besedilni pogovori
Medtem ko je besedilo prevladovalo pri razvoju pogovorne umetne inteligence, smo v zadnjih letih opazili pritisk k večmodalnim sistemom, ki lahko razumejo in ustvarjajo več vrst medijev. Ta razvoj odraža temeljno resnico o človeški komunikaciji – ne uporabljamo le besed; gestikuliramo, prikazujemo slike, rišemo diagrame in uporabljamo svoje okolje za prenos pomena.
Modeli v jeziku vida, kot so DALL-E, Midjourney in Stable Diffusion, so pokazali sposobnost generiranja slik iz besedilnih opisov, medtem ko so modeli, kot je GPT-4 z zmogljivostmi vida, lahko analizirali slike in o njih inteligentno razpravljali. To je odprlo nove možnosti za pogovorne vmesnike:
Boti za pomoč strankam, ki lahko analizirajo fotografije poškodovanih izdelkov
Nakupovalni pomočniki, ki lahko prepoznajo predmete na slikah in poiščejo podobne izdelke
Izobraževalna orodja, ki lahko razložijo diagrame in vizualne koncepte
Funkcije dostopnosti, ki lahko opišejo slike za slabovidne uporabnike
Močno so napredovale tudi glasovne zmogljivosti. Zgodnji govorni vmesniki, kot so sistemi IVR (Interactive Voice Response), so bili znano frustrirajoči, omejeni na toge ukaze in strukture menijev. Sodobni glasovni pomočniki lahko razumejo naravne govorne vzorce, upoštevajo različne poudarke in govorne motnje ter se odzovejo z vse bolj naravno zvenečimi sintetiziranimi glasovi.
Zlitje teh zmožnosti ustvarja resnično multimodalni pogovorni AI, ki lahko nemoteno preklaplja med različnimi komunikacijskimi načini glede na kontekst in potrebe uporabnikov. Uporabnik lahko začne z besedilnim vprašanjem o popravljanju svojega tiskalnika, pošlje fotografijo sporočila o napaki, prejme diagram, ki poudarja ustrezne gumbe, in nato preklopi na glasovna navodila, medtem ko so njegove roke zaposlene s popravilom.
Ta multimodalni pristop ne predstavlja le tehničnega napredka, temveč temeljni premik k bolj naravni interakciji med človekom in računalnikom – srečanje z uporabniki v katerem koli načinu komunikacije najbolje deluje za njihov trenutni kontekst in potrebe.
Modeli v jeziku vida, kot so DALL-E, Midjourney in Stable Diffusion, so pokazali sposobnost generiranja slik iz besedilnih opisov, medtem ko so modeli, kot je GPT-4 z zmogljivostmi vida, lahko analizirali slike in o njih inteligentno razpravljali. To je odprlo nove možnosti za pogovorne vmesnike:
Boti za pomoč strankam, ki lahko analizirajo fotografije poškodovanih izdelkov
Nakupovalni pomočniki, ki lahko prepoznajo predmete na slikah in poiščejo podobne izdelke
Izobraževalna orodja, ki lahko razložijo diagrame in vizualne koncepte
Funkcije dostopnosti, ki lahko opišejo slike za slabovidne uporabnike
Močno so napredovale tudi glasovne zmogljivosti. Zgodnji govorni vmesniki, kot so sistemi IVR (Interactive Voice Response), so bili znano frustrirajoči, omejeni na toge ukaze in strukture menijev. Sodobni glasovni pomočniki lahko razumejo naravne govorne vzorce, upoštevajo različne poudarke in govorne motnje ter se odzovejo z vse bolj naravno zvenečimi sintetiziranimi glasovi.
Zlitje teh zmožnosti ustvarja resnično multimodalni pogovorni AI, ki lahko nemoteno preklaplja med različnimi komunikacijskimi načini glede na kontekst in potrebe uporabnikov. Uporabnik lahko začne z besedilnim vprašanjem o popravljanju svojega tiskalnika, pošlje fotografijo sporočila o napaki, prejme diagram, ki poudarja ustrezne gumbe, in nato preklopi na glasovna navodila, medtem ko so njegove roke zaposlene s popravilom.
Ta multimodalni pristop ne predstavlja le tehničnega napredka, temveč temeljni premik k bolj naravni interakciji med človekom in računalnikom – srečanje z uporabniki v katerem koli načinu komunikacije najbolje deluje za njihov trenutni kontekst in potrebe.
Generacija s povečano pridobitvijo: Umetna inteligenca temelji na dejstvih
Kljub impresivnim zmogljivostim imajo veliki jezikovni modeli inherentne omejitve. Lahko "halucinirajo" informacije in samozavestno navajajo zveneča verjetna, a napačna dejstva. Njihovo znanje je omejeno na podatke o njihovem usposabljanju, kar ustvarja mejni datum znanja. In nimajo zmožnosti dostopa do informacij v realnem času ali specializiranih podatkovnih zbirk, razen če so posebej zasnovane za to.
Retrieval-Augmented Generation (RAG) se je pojavila kot rešitev za te izzive. Namesto da bi se zanašali zgolj na parametre, pridobljene med usposabljanjem, sistemi RAG združujejo generativne sposobnosti jezikovnih modelov z mehanizmi za iskanje, ki lahko dostopajo do zunanjih virov znanja.
Tipična RAG arhitektura deluje takole:
Sistem prejme povpraševanje uporabnika
V ustreznih bazah znanja išče informacije, ki se nanašajo na poizvedbo
Jezikovnemu modelu posreduje poizvedbo in pridobljene informacije
Model ustvari odziv, ki temelji na pridobljenih dejstvih
Ta pristop ponuja več prednosti:
Natančnejši, dejanski odgovori z utemeljitvijo ustvarjanja na preverjenih informacijah
Možnost dostopa do posodobljenih informacij, ki presegajo omejitev usposabljanja modela
Specializirano znanje iz virov, specifičnih za področje, kot je dokumentacija podjetja
Preglednost in pripisovanje z navajanjem virov informacij
Za podjetja, ki izvajajo pogovorno umetno inteligenco, se je RAG izkazal za posebej dragocenega za aplikacije storitev za stranke. Bančni klepetalni robot lahko na primer dostopa do najnovejših političnih dokumentov, informacij o računu in evidenc o transakcijah, da zagotovi natančne, prilagojene odgovore, ki bi bili nemogoči s samostojnim jezikovnim modelom.
Razvoj sistemov RAG se nadaljuje z izboljšavami v natančnosti iskanja, bolj sofisticiranimi metodami za integracijo pridobljenih informacij z ustvarjenim besedilom in boljšimi mehanizmi za ocenjevanje zanesljivosti različnih virov informacij.
Retrieval-Augmented Generation (RAG) se je pojavila kot rešitev za te izzive. Namesto da bi se zanašali zgolj na parametre, pridobljene med usposabljanjem, sistemi RAG združujejo generativne sposobnosti jezikovnih modelov z mehanizmi za iskanje, ki lahko dostopajo do zunanjih virov znanja.
Tipična RAG arhitektura deluje takole:
Sistem prejme povpraševanje uporabnika
V ustreznih bazah znanja išče informacije, ki se nanašajo na poizvedbo
Jezikovnemu modelu posreduje poizvedbo in pridobljene informacije
Model ustvari odziv, ki temelji na pridobljenih dejstvih
Ta pristop ponuja več prednosti:
Natančnejši, dejanski odgovori z utemeljitvijo ustvarjanja na preverjenih informacijah
Možnost dostopa do posodobljenih informacij, ki presegajo omejitev usposabljanja modela
Specializirano znanje iz virov, specifičnih za področje, kot je dokumentacija podjetja
Preglednost in pripisovanje z navajanjem virov informacij
Za podjetja, ki izvajajo pogovorno umetno inteligenco, se je RAG izkazal za posebej dragocenega za aplikacije storitev za stranke. Bančni klepetalni robot lahko na primer dostopa do najnovejših političnih dokumentov, informacij o računu in evidenc o transakcijah, da zagotovi natančne, prilagojene odgovore, ki bi bili nemogoči s samostojnim jezikovnim modelom.
Razvoj sistemov RAG se nadaljuje z izboljšavami v natančnosti iskanja, bolj sofisticiranimi metodami za integracijo pridobljenih informacij z ustvarjenim besedilom in boljšimi mehanizmi za ocenjevanje zanesljivosti različnih virov informacij.
Model sodelovanja človek-AI: Iskanje pravega ravnovesja
Ko so se pogovorne zmožnosti AI razširile, se je odnos med ljudmi in sistemi AI razvil. Zgodnji chatboti so bili jasno postavljeni kot orodja – omejenega obsega in očitno nečloveških interakcij. Sodobni sistemi zabrišejo te meje in ustvarjajo nova vprašanja o tem, kako oblikovati učinkovito sodelovanje človeka in umetne inteligence.
Najuspešnejše izvedbe danes sledijo modelu sodelovanja, kjer:
AI obravnava rutinske, ponavljajoče se poizvedbe, ki ne zahtevajo človeške presoje
Ljudje se osredotočamo na zapletene primere, ki zahtevajo empatijo, etično razmišljanje ali kreativno reševanje problemov
Sistem pozna svoje omejitve in se gladko stopnjuje do človeških agentov, kadar je to primerno
Prehod med AI in človeško podporo je za uporabnika nemoten
Človeški agenti imajo popoln kontekst zgodovine pogovorov z AI
AI se še naprej uči iz človeških posegov in postopoma širi svoje zmogljivosti
Ta pristop priznava, da pogovorna umetna inteligenca ne bi smela stremeti k temu, da bi v celoti nadomestila človeško interakcijo, temveč da bi jo dopolnila – obravnavala bi obsežne, enostavne poizvedbe, ki porabljajo čas človeških agentov, hkrati pa zagotavljala, da zapletena vprašanja dosežejo pravo človeško strokovno znanje.
Implementacija tega modela se razlikuje glede na panoge. V zdravstvu lahko klepetalni roboti z umetno inteligenco urejajo načrtovanje sestankov in osnovne preglede simptomov, hkrati pa zagotavljajo, da zdravniški nasveti prihajajo od usposobljenih strokovnjakov. V pravnih storitvah lahko umetna inteligenca pomaga pri pripravi dokumentov in raziskovanju, medtem ko tolmačenje in strategijo prepušča odvetnikom. Pri storitvah za stranke lahko umetna inteligenca razreši običajne težave, medtem ko zapletene težave usmerja k specializiranim agentom.
Ko zmogljivosti umetne inteligence še naprej napredujejo, se bo meja med tem, kar zahteva človeško sodelovanje, in tem, kar je mogoče avtomatizirati, premaknila, vendar temeljno načelo ostaja: učinkovita umetna inteligenca za pogovore bi morala izboljšati človeške zmožnosti, ne pa jih preprosto nadomestiti.
Najuspešnejše izvedbe danes sledijo modelu sodelovanja, kjer:
AI obravnava rutinske, ponavljajoče se poizvedbe, ki ne zahtevajo človeške presoje
Ljudje se osredotočamo na zapletene primere, ki zahtevajo empatijo, etično razmišljanje ali kreativno reševanje problemov
Sistem pozna svoje omejitve in se gladko stopnjuje do človeških agentov, kadar je to primerno
Prehod med AI in človeško podporo je za uporabnika nemoten
Človeški agenti imajo popoln kontekst zgodovine pogovorov z AI
AI se še naprej uči iz človeških posegov in postopoma širi svoje zmogljivosti
Ta pristop priznava, da pogovorna umetna inteligenca ne bi smela stremeti k temu, da bi v celoti nadomestila človeško interakcijo, temveč da bi jo dopolnila – obravnavala bi obsežne, enostavne poizvedbe, ki porabljajo čas človeških agentov, hkrati pa zagotavljala, da zapletena vprašanja dosežejo pravo človeško strokovno znanje.
Implementacija tega modela se razlikuje glede na panoge. V zdravstvu lahko klepetalni roboti z umetno inteligenco urejajo načrtovanje sestankov in osnovne preglede simptomov, hkrati pa zagotavljajo, da zdravniški nasveti prihajajo od usposobljenih strokovnjakov. V pravnih storitvah lahko umetna inteligenca pomaga pri pripravi dokumentov in raziskovanju, medtem ko tolmačenje in strategijo prepušča odvetnikom. Pri storitvah za stranke lahko umetna inteligenca razreši običajne težave, medtem ko zapletene težave usmerja k specializiranim agentom.
Ko zmogljivosti umetne inteligence še naprej napredujejo, se bo meja med tem, kar zahteva človeško sodelovanje, in tem, kar je mogoče avtomatizirati, premaknila, vendar temeljno načelo ostaja: učinkovita umetna inteligenca za pogovore bi morala izboljšati človeške zmožnosti, ne pa jih preprosto nadomestiti.
Prihodnja pokrajina: kam pelje pogovorna umetna inteligenca
Ko gledamo na obzorje, več nastajajočih trendov kroji prihodnost pogovorne umetne inteligence. Ta razvoj ne obljublja le postopnih izboljšav, ampak potencialno transformativne spremembe v našem komuniciranju s tehnologijo.
Personalizacija v velikem obsegu: Prihodnji sistemi bodo vedno bolj prilagajali svoje odzive ne le neposrednemu kontekstu, temveč komunikacijskemu slogu, preferencam, ravni znanja in zgodovini odnosov vsakega uporabnika. Zaradi te personalizacije se bodo interakcije počutile bolj naravne in ustrezne, čeprav odpira pomembna vprašanja o zasebnosti in uporabi podatkov.
Čustvena inteligenca: Medtem ko lahko današnji sistemi zaznajo osnovna čustva, bo umetna inteligenca za pogovore v prihodnosti razvila bolj sofisticirano čustveno inteligenco – prepoznavanje subtilnih čustvenih stanj, ustrezno odzivanje na stisko ali frustracijo ter ustrezno prilagajanje tona in pristopa. Ta zmožnost bo še posebej dragocena pri storitvah za stranke, zdravstvu in izobraževalnih aplikacijah.
Proaktivna pomoč: Namesto čakanja na eksplicitne poizvedbe bodo pogovorni sistemi naslednje generacije predvidevali potrebe na podlagi konteksta, uporabniške zgodovine in okoljskih signalov. Sistem lahko opazi, da načrtujete več sestankov v neznanem mestu, in proaktivno ponudi možnosti prevoza ali vremensko napoved.
Brezhibna večmodalna integracija: Prihodnji sistemi bodo presegli zgolj podporo različnih modalitet in jih brezhibno integrirali. Pogovor lahko naravno teče med besedilom, glasom, slikami in interaktivnimi elementi, pri čemer se za vsako informacijo izbere pravi način, ne da bi bilo treba izrecno izbrati uporabnika.
Strokovnjaki za specializirana področja: Medtem ko se bodo pomočniki za splošne namene še naprej izboljševali, bomo priča tudi vzponu visoko specializiranega pogovornega umetne inteligence z globokim strokovnim znanjem na določenih področjih – pravni pomočniki, ki razumejo sodno prakso in precedenčne primere, medicinski sistemi s celovitim znanjem o medsebojnem delovanju zdravil in protokolih zdravljenja ali finančni svetovalci, ki so seznanjeni z davčnimi zakoni in naložbenimi strategijami.
Resnično nenehno učenje: Prihodnji sistemi bodo presegli periodično prekvalificiranje in se bodo preusmerili k stalnemu učenju iz interakcij, sčasoma pa bodo postali bolj koristni in prilagojeni, hkrati pa bodo ohranili ustrezne varovalke zasebnosti.
Kljub tem vznemirljivim možnostim ostajajo izzivi. Pomisleki glede zasebnosti, ublažitev pristranskosti, ustrezna preglednost in vzpostavitev prave ravni človeškega nadzora so stalna vprašanja, ki bodo oblikovala tako tehnologijo kot njeno ureditev. Najuspešnejše izvedbe bodo tiste, ki bodo te izzive obravnavale premišljeno, hkrati pa uporabnikom zagotavljale resnično vrednost.
Jasno je, da se je pogovorna umetna inteligenca premaknila iz nišne tehnologije v paradigmo glavnega vmesnika, ki bo vedno bolj posredovala pri naših interakcijah z digitalnimi sistemi. Evolucijska pot od ELIZA-inega preprostega ujemanja vzorcev do današnjih sofisticiranih jezikovnih modelov predstavlja enega najpomembnejših napredkov v interakciji med človekom in računalnikom – in poti še zdaleč ni konec.
Personalizacija v velikem obsegu: Prihodnji sistemi bodo vedno bolj prilagajali svoje odzive ne le neposrednemu kontekstu, temveč komunikacijskemu slogu, preferencam, ravni znanja in zgodovini odnosov vsakega uporabnika. Zaradi te personalizacije se bodo interakcije počutile bolj naravne in ustrezne, čeprav odpira pomembna vprašanja o zasebnosti in uporabi podatkov.
Čustvena inteligenca: Medtem ko lahko današnji sistemi zaznajo osnovna čustva, bo umetna inteligenca za pogovore v prihodnosti razvila bolj sofisticirano čustveno inteligenco – prepoznavanje subtilnih čustvenih stanj, ustrezno odzivanje na stisko ali frustracijo ter ustrezno prilagajanje tona in pristopa. Ta zmožnost bo še posebej dragocena pri storitvah za stranke, zdravstvu in izobraževalnih aplikacijah.
Proaktivna pomoč: Namesto čakanja na eksplicitne poizvedbe bodo pogovorni sistemi naslednje generacije predvidevali potrebe na podlagi konteksta, uporabniške zgodovine in okoljskih signalov. Sistem lahko opazi, da načrtujete več sestankov v neznanem mestu, in proaktivno ponudi možnosti prevoza ali vremensko napoved.
Brezhibna večmodalna integracija: Prihodnji sistemi bodo presegli zgolj podporo različnih modalitet in jih brezhibno integrirali. Pogovor lahko naravno teče med besedilom, glasom, slikami in interaktivnimi elementi, pri čemer se za vsako informacijo izbere pravi način, ne da bi bilo treba izrecno izbrati uporabnika.
Strokovnjaki za specializirana področja: Medtem ko se bodo pomočniki za splošne namene še naprej izboljševali, bomo priča tudi vzponu visoko specializiranega pogovornega umetne inteligence z globokim strokovnim znanjem na določenih področjih – pravni pomočniki, ki razumejo sodno prakso in precedenčne primere, medicinski sistemi s celovitim znanjem o medsebojnem delovanju zdravil in protokolih zdravljenja ali finančni svetovalci, ki so seznanjeni z davčnimi zakoni in naložbenimi strategijami.
Resnično nenehno učenje: Prihodnji sistemi bodo presegli periodično prekvalificiranje in se bodo preusmerili k stalnemu učenju iz interakcij, sčasoma pa bodo postali bolj koristni in prilagojeni, hkrati pa bodo ohranili ustrezne varovalke zasebnosti.
Kljub tem vznemirljivim možnostim ostajajo izzivi. Pomisleki glede zasebnosti, ublažitev pristranskosti, ustrezna preglednost in vzpostavitev prave ravni človeškega nadzora so stalna vprašanja, ki bodo oblikovala tako tehnologijo kot njeno ureditev. Najuspešnejše izvedbe bodo tiste, ki bodo te izzive obravnavale premišljeno, hkrati pa uporabnikom zagotavljale resnično vrednost.
Jasno je, da se je pogovorna umetna inteligenca premaknila iz nišne tehnologije v paradigmo glavnega vmesnika, ki bo vedno bolj posredovala pri naših interakcijah z digitalnimi sistemi. Evolucijska pot od ELIZA-inega preprostega ujemanja vzorcev do današnjih sofisticiranih jezikovnih modelov predstavlja enega najpomembnejših napredkov v interakciji med človekom in računalnikom – in poti še zdaleč ni konec.




