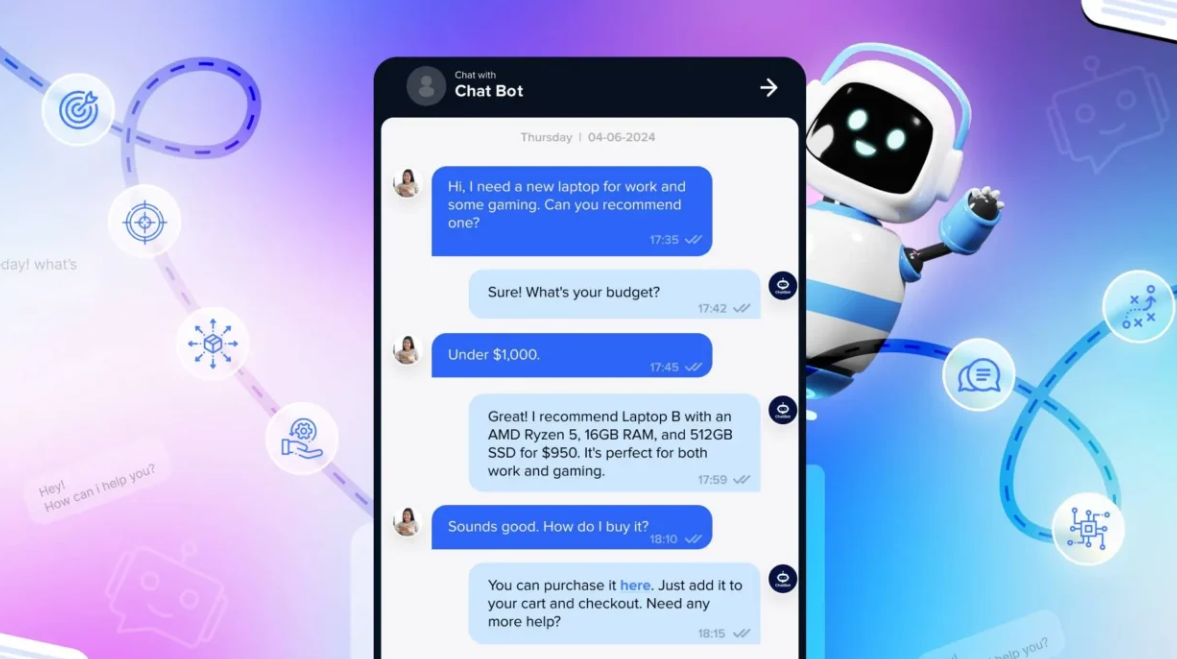
Testirajte AI na VAŠI spletni strani v 60 sekundah
Poglejte, kako naša umetna inteligenca takoj analizira vašo spletno stran in ustvari personaliziranega chatbota - brez registracije. Samo vnesite svoj URL in opazujte, kako deluje!
Pripravljeno v 60 sekundah
Brez potrebe po kodiranju
100% varno
Paradoks zasebnosti sodobnih pomočnikov AI
Sprejeli smo jih v svoje domove, pisarne in žepe. Ves dan jim postavljamo vprašanja, zahtevamo, da predvajajo naše najljubše pesmi, in jim zaupamo nadzor nad našimi pametnimi domovi. Pogovorni vmesniki, ki jih poganja umetna inteligenca, so postali tako integrirani v vsakdanje življenje, da mnogi od nas komunicirajo z več pomočniki umetne inteligence več desetkrat vsak dan, ne da bi pomislili.
Vendar pa se za temi brezhibnimi interakcijami skriva kompleksna pokrajina zasebnosti, ki jo malo uporabnikov popolnoma razume. Sama narava pogovorne umetne inteligence ustvarja temeljno napetost: ti sistemi potrebujejo podatke – pogosto osebne, včasih občutljive – za učinkovito delovanje, vendar to isto zbiranje podatkov ustvarja pomembne posledice za zasebnost, ki jih ni mogoče prezreti.
Ta napetost predstavlja tisto, kar raziskovalci zasebnosti imenujejo "paradoks funkcionalnost-zasebnost". Za zagotavljanje prilagojenih, kontekstualno ustreznih odgovorov morajo pomočniki AI vedeti za vas. Vaše nastavitve, zgodovina, lokacija in navade prispevajo k bolj koristnim interakcijam. Toda vsaka zbrana informacija predstavlja potencialno izpostavljenost zasebnosti, ki jo je treba skrbno upravljati in zaščititi.
Vložki še nikoli niso bili višji. Ko pogovorni vmesniki presegajo preproste ukaze (»Nastavi časovnik za 10 minut«) k zapletenim interakcijam, ki se zavedajo konteksta (»Opomni me, naj opozorim na to težavo iz e-pošte prejšnjega tedna, ko se jutri srečam s Sarah«), posledice za zasebnost eksponentno rastejo. Ti sistemi ne obdelujejo več le izoliranih zahtev, temveč gradijo celovite uporabniške modele, ki zajemajo več področij našega življenja.
Za razvijalce, podjetja in uporabnike, ki krmarijo po tej pokrajini, je razumevanje edinstvenih izzivov zasebnosti konverzacijske umetne inteligence prvi korak k odgovorni implementaciji in uporabi. Raziščimo ta kompleksen teren in strategije, ki se pojavljajo za ravnovesje zmogljive funkcionalnosti z zanesljivo zaščito zasebnosti.
Vendar pa se za temi brezhibnimi interakcijami skriva kompleksna pokrajina zasebnosti, ki jo malo uporabnikov popolnoma razume. Sama narava pogovorne umetne inteligence ustvarja temeljno napetost: ti sistemi potrebujejo podatke – pogosto osebne, včasih občutljive – za učinkovito delovanje, vendar to isto zbiranje podatkov ustvarja pomembne posledice za zasebnost, ki jih ni mogoče prezreti.
Ta napetost predstavlja tisto, kar raziskovalci zasebnosti imenujejo "paradoks funkcionalnost-zasebnost". Za zagotavljanje prilagojenih, kontekstualno ustreznih odgovorov morajo pomočniki AI vedeti za vas. Vaše nastavitve, zgodovina, lokacija in navade prispevajo k bolj koristnim interakcijam. Toda vsaka zbrana informacija predstavlja potencialno izpostavljenost zasebnosti, ki jo je treba skrbno upravljati in zaščititi.
Vložki še nikoli niso bili višji. Ko pogovorni vmesniki presegajo preproste ukaze (»Nastavi časovnik za 10 minut«) k zapletenim interakcijam, ki se zavedajo konteksta (»Opomni me, naj opozorim na to težavo iz e-pošte prejšnjega tedna, ko se jutri srečam s Sarah«), posledice za zasebnost eksponentno rastejo. Ti sistemi ne obdelujejo več le izoliranih zahtev, temveč gradijo celovite uporabniške modele, ki zajemajo več področij našega življenja.
Za razvijalce, podjetja in uporabnike, ki krmarijo po tej pokrajini, je razumevanje edinstvenih izzivov zasebnosti konverzacijske umetne inteligence prvi korak k odgovorni implementaciji in uporabi. Raziščimo ta kompleksen teren in strategije, ki se pojavljajo za ravnovesje zmogljive funkcionalnosti z zanesljivo zaščito zasebnosti.
Razumevanje, kaj se v resnici dogaja z vašimi glasovnimi podatki
Kaj se dejansko zgodi z vašimi podatki, ko komunicirate s pogovornim sistemom AI? Pot je bolj zapletena – in pogosto obsežnejša – kot se mnogi uporabniki zavedajo.
Postopek se običajno začne z zajemanjem podatkov. Glasovni sistemi pretvorijo zvok v digitalne signale, medtem ko besedilni vmesniki zajemajo tipkane vnose. Ti neobdelani podatki so nato podvrženi več stopnjam obdelave, ki lahko vključujejo:
Pretvorba govora v besedilo za glasovne vnose
Obdelava naravnega jezika za določitev namena
Analiza konteksta, ki lahko vključuje prejšnje interakcije
Generiranje odziva na podlagi usposobljenih modelov AI
Dodatna obdelava za personalizacijo
Shranjevanje interakcij za izboljšanje sistema
Vsaka stopnja predstavlja različne vidike zasebnosti. Na primer, kje poteka pretvorba govora v besedilo – v vaši napravi ali na oddaljenih strežnikih? Ali so posnetki vašega glasu shranjeni in če so, kako dolgo? Kdo bi lahko imel dostop do teh posnetkov? Ali sistem nenehno posluša ali samo po besedi za bujenje?
Večji ponudniki imajo različne pristope k tem vprašanjem. Nekateri obdelujejo vse podatke v oblaku, drugi pa izvajajo začetno obdelavo na napravi, da omejijo prenos podatkov. Politike shranjevanja se zelo razlikujejo, od hrambe za nedoločen čas do samodejnega izbrisa po določenih obdobjih. Kontrole dostopa segajo od stroge omejitve do pooblaščene uporabe s strani pregledovalcev za izboljšanje kakovosti.
Resničnost je taka, da tudi če imajo podjetja stroge politike zasebnosti, inherentna zapletenost teh sistemov uporabnikom otežuje ohranjanje jasne vidljivosti, kako natančno se uporabljajo njihovi podatki. Nedavna razkritja o človeških pregledovalcih, ki poslušajo posnetke glasovnega pomočnika, so presenetila številne uporabnike, ki so domnevali, da so njihove interakcije ostale povsem zasebne ali pa jih obdelujejo samo avtomatizirani sistemi.
Dodatek k tej kompleksnosti je porazdeljena narava sodobnih pomočnikov AI. Ko svoj pametni zvočnik vprašate o bližnjih restavracijah, lahko ta poizvedba vpliva na več sistemov – pomočnikovo osnovno umetno inteligenco, storitve kartiranja, zbirke podatkov o restavracijah, platforme za pregledovanje – vsak ima svoje lastne prakse podatkov in posledice za zasebnost.
Da bi uporabniki sprejemali ozaveščene odločitve, je bistvena večja preglednost teh postopkov. Nekateri ponudniki so napredovali v tej smeri, saj ponujajo jasnejše razlage podatkovnih praks, natančnejše kontrole zasebnosti in možnosti za pregledovanje in brisanje zgodovinskih podatkov. Vendar ostajajo precejšnje vrzeli pri pomoči uporabnikom za resnično razumevanje posledic njihove vsakodnevne interakcije z umetno inteligenco na zasebnost.
Postopek se običajno začne z zajemanjem podatkov. Glasovni sistemi pretvorijo zvok v digitalne signale, medtem ko besedilni vmesniki zajemajo tipkane vnose. Ti neobdelani podatki so nato podvrženi več stopnjam obdelave, ki lahko vključujejo:
Pretvorba govora v besedilo za glasovne vnose
Obdelava naravnega jezika za določitev namena
Analiza konteksta, ki lahko vključuje prejšnje interakcije
Generiranje odziva na podlagi usposobljenih modelov AI
Dodatna obdelava za personalizacijo
Shranjevanje interakcij za izboljšanje sistema
Vsaka stopnja predstavlja različne vidike zasebnosti. Na primer, kje poteka pretvorba govora v besedilo – v vaši napravi ali na oddaljenih strežnikih? Ali so posnetki vašega glasu shranjeni in če so, kako dolgo? Kdo bi lahko imel dostop do teh posnetkov? Ali sistem nenehno posluša ali samo po besedi za bujenje?
Večji ponudniki imajo različne pristope k tem vprašanjem. Nekateri obdelujejo vse podatke v oblaku, drugi pa izvajajo začetno obdelavo na napravi, da omejijo prenos podatkov. Politike shranjevanja se zelo razlikujejo, od hrambe za nedoločen čas do samodejnega izbrisa po določenih obdobjih. Kontrole dostopa segajo od stroge omejitve do pooblaščene uporabe s strani pregledovalcev za izboljšanje kakovosti.
Resničnost je taka, da tudi če imajo podjetja stroge politike zasebnosti, inherentna zapletenost teh sistemov uporabnikom otežuje ohranjanje jasne vidljivosti, kako natančno se uporabljajo njihovi podatki. Nedavna razkritja o človeških pregledovalcih, ki poslušajo posnetke glasovnega pomočnika, so presenetila številne uporabnike, ki so domnevali, da so njihove interakcije ostale povsem zasebne ali pa jih obdelujejo samo avtomatizirani sistemi.
Dodatek k tej kompleksnosti je porazdeljena narava sodobnih pomočnikov AI. Ko svoj pametni zvočnik vprašate o bližnjih restavracijah, lahko ta poizvedba vpliva na več sistemov – pomočnikovo osnovno umetno inteligenco, storitve kartiranja, zbirke podatkov o restavracijah, platforme za pregledovanje – vsak ima svoje lastne prakse podatkov in posledice za zasebnost.
Da bi uporabniki sprejemali ozaveščene odločitve, je bistvena večja preglednost teh postopkov. Nekateri ponudniki so napredovali v tej smeri, saj ponujajo jasnejše razlage podatkovnih praks, natančnejše kontrole zasebnosti in možnosti za pregledovanje in brisanje zgodovinskih podatkov. Vendar ostajajo precejšnje vrzeli pri pomoči uporabnikom za resnično razumevanje posledic njihove vsakodnevne interakcije z umetno inteligenco na zasebnost.
Regulativna pokrajina: razvija se, a nedosledno
Pogovorna umetna inteligenca deluje v regulativnem okolju, ki se hkrati hitro razvija in je frustrirajoče razdrobljeno. Različne regije so vzpostavile različne pristope k zasebnosti podatkov, ki neposredno vplivajo na to, kako je mogoče oblikovati in uporabljati pogovorne vmesnike.
Splošna uredba Evropske unije o varstvu podatkov (GDPR) predstavlja enega najobsežnejših okvirov, ki vzpostavlja načela, ki pomembno vplivajo na pogovorno umetno inteligenco:
Zahteva po posebnem informiranem soglasju pred obdelavo osebnih podatkov
Načela minimiziranja podatkov, ki omejujejo zbiranje na potrebno
Omejitev namena, ki omejuje uporabo podatkov zunaj navedenih namenov
Pravica do dostopa do osebnih podatkov, ki jih imajo podjetja
Pravica do pozabe (izbris podatkov na zahtevo)
Zahteve za prenosljivost podatkov med storitvami
Te zahteve predstavljajo posebne izzive za pogovorno umetno inteligenco, ki se pogosto zanaša na široko zbiranje podatkov in se lahko spopade z jasno omejitvijo namena, ko so sistemi zasnovani za obravnavanje različnih in nepredvidljivih zahtev.
V Združenih državah je ureditev zasebnosti še vedno bolj razdrobljena, saj kalifornijski zakon o zasebnosti potrošnikov (CCPA) in njegov naslednik kalifornijski zakon o zasebnosti (CPRA) vzpostavljata najmočnejšo zaščito na državni ravni. Ti predpisi zagotavljajo prebivalcem Kalifornije pravice, podobne tistim iz GDPR, vključno z dostopom do osebnih podatkov in pravico do izbrisa podatkov. Druge države so sledile s svojo lastno zakonodajo in ustvarile kup zahtev po vsej državi.
Posebni predpisi dodajajo dodatno zapletenost. V kontekstu zdravstvenega varstva predpisi HIPAA v ZDA nalagajo stroge zahteve glede ravnanja z zdravstvenimi informacijami. Za storitve, namenjene otrokom, COPPA vzpostavlja dodatne zaščite, ki omejujejo zbiranje in uporabo podatkov.
Globalna narava večine pogovornih storitev umetne inteligence pomeni, da morajo podjetja običajno načrtovati najstrožje veljavne predpise, medtem ko upravljajo skladnost v več jurisdikcijah. Ta zapletena pokrajina ustvarja izzive tako za uveljavljena podjetja, ki krmarijo z različnimi zahtevami, kot za startupe z omejenimi pravnimi viri.
Za uporabnike nedosledno regulativno okolje pomeni, da se lahko zaščita zasebnosti zelo razlikuje glede na to, kje živijo. Tisti v regijah z močno zakonodajo o varstvu podatkov imajo na splošno več pravic v zvezi s svojimi pogovornimi podatki AI, medtem ko imajo drugi morda manj pravne zaščite.
Regulativno okolje se še naprej razvija, v številnih regijah pa se razvija nova zakonodaja, ki posebej obravnava upravljanje umetne inteligence. Ta nastajajoča ogrodja lahko zagotovijo bolj prilagojene pristope k edinstvenim izzivom zasebnosti pogovorne umetne inteligence, ki lahko vzpostavijo jasnejše standarde za soglasje, preglednost in upravljanje podatkov v teh vse pomembnejših sistemih.
Splošna uredba Evropske unije o varstvu podatkov (GDPR) predstavlja enega najobsežnejših okvirov, ki vzpostavlja načela, ki pomembno vplivajo na pogovorno umetno inteligenco:
Zahteva po posebnem informiranem soglasju pred obdelavo osebnih podatkov
Načela minimiziranja podatkov, ki omejujejo zbiranje na potrebno
Omejitev namena, ki omejuje uporabo podatkov zunaj navedenih namenov
Pravica do dostopa do osebnih podatkov, ki jih imajo podjetja
Pravica do pozabe (izbris podatkov na zahtevo)
Zahteve za prenosljivost podatkov med storitvami
Te zahteve predstavljajo posebne izzive za pogovorno umetno inteligenco, ki se pogosto zanaša na široko zbiranje podatkov in se lahko spopade z jasno omejitvijo namena, ko so sistemi zasnovani za obravnavanje različnih in nepredvidljivih zahtev.
V Združenih državah je ureditev zasebnosti še vedno bolj razdrobljena, saj kalifornijski zakon o zasebnosti potrošnikov (CCPA) in njegov naslednik kalifornijski zakon o zasebnosti (CPRA) vzpostavljata najmočnejšo zaščito na državni ravni. Ti predpisi zagotavljajo prebivalcem Kalifornije pravice, podobne tistim iz GDPR, vključno z dostopom do osebnih podatkov in pravico do izbrisa podatkov. Druge države so sledile s svojo lastno zakonodajo in ustvarile kup zahtev po vsej državi.
Posebni predpisi dodajajo dodatno zapletenost. V kontekstu zdravstvenega varstva predpisi HIPAA v ZDA nalagajo stroge zahteve glede ravnanja z zdravstvenimi informacijami. Za storitve, namenjene otrokom, COPPA vzpostavlja dodatne zaščite, ki omejujejo zbiranje in uporabo podatkov.
Globalna narava večine pogovornih storitev umetne inteligence pomeni, da morajo podjetja običajno načrtovati najstrožje veljavne predpise, medtem ko upravljajo skladnost v več jurisdikcijah. Ta zapletena pokrajina ustvarja izzive tako za uveljavljena podjetja, ki krmarijo z različnimi zahtevami, kot za startupe z omejenimi pravnimi viri.
Za uporabnike nedosledno regulativno okolje pomeni, da se lahko zaščita zasebnosti zelo razlikuje glede na to, kje živijo. Tisti v regijah z močno zakonodajo o varstvu podatkov imajo na splošno več pravic v zvezi s svojimi pogovornimi podatki AI, medtem ko imajo drugi morda manj pravne zaščite.
Regulativno okolje se še naprej razvija, v številnih regijah pa se razvija nova zakonodaja, ki posebej obravnava upravljanje umetne inteligence. Ta nastajajoča ogrodja lahko zagotovijo bolj prilagojene pristope k edinstvenim izzivom zasebnosti pogovorne umetne inteligence, ki lahko vzpostavijo jasnejše standarde za soglasje, preglednost in upravljanje podatkov v teh vse pomembnejših sistemih.
Tehnični izzivi pogovorne umetne inteligence, ki ohranja zasebnost
Gradnja pogovorne umetne inteligence, ki spoštuje zasebnost in hkrati ohranja visoko funkcionalnost, predstavlja pomembne tehnične izzive. Ti sistemi so se tradicionalno zanašali na centralizirano obdelavo v oblaku in obsežno zbiranje podatkov – pristopi, ki so lahko v nasprotju z najboljšimi praksami glede zasebnosti.
Več ključnih tehničnih izzivov stoji na presečišču pogovorne umetne inteligence in zasebnosti:
Obdelava v napravi v primerjavi z računalništvom v oblaku
Premik obdelave iz oblaka v napravo (robno računalništvo) lahko bistveno izboljša zasebnost, tako da občutljive podatke ohranja lokalno. Vendar se ta pristop sooča z bistvenimi omejitvami:
Mobilne in domače naprave imajo omejene računalniške vire v primerjavi z infrastrukturo v oblaku
Večji modeli AI morda ne bodo ustrezali potrošniškim napravam
Modeli v napravi lahko zagotovijo manj kakovostne odzive brez dostopa do centraliziranega učenja
Pogoste posodobitve modela lahko porabijo veliko pasovne širine in prostora za shranjevanje
Kljub tem izzivom napredek pri stiskanju modelov in specializirani strojni opremi z umetno inteligenco omogočata, da je obdelava v napravi vedno bolj izvedljiva. Nekateri sistemi zdaj uporabljajo hibridne pristope, ki izvajajo začetno obdelavo lokalno in pošiljajo samo potrebne podatke v oblak.
Strojno učenje, ki varuje zasebnost
Tradicionalni pristopi strojnega učenja so bili osredotočeni na centralizirano zbiranje podatkov, vendar se pojavljajo alternative, osredotočene na zasebnost:
Zvezno učenje omogoča usposabljanje modelov v številnih napravah, medtem ko so osebni podatki lokalni. Z osrednjimi strežniki se delijo samo posodobitve modela (ne uporabniški podatki), kar ščiti zasebnost posameznikov, hkrati pa omogoča izboljšanje sistema.
Diferencialna zasebnost uvaja izračunani šum v nize podatkov ali poizvedbe, da prepreči identifikacijo posameznikov, hkrati pa ohranja statistično veljavnost za usposabljanje in analizo.
Varno večstransko računanje omogoča analizo v več virih podatkov, ne da bi bilo treba kateri koli strani razkriti svoje neobdelane podatke drugim.
Te tehnike obetajo, vendar prinašajo kompromise v računalniški učinkovitosti, kompleksnosti implementacije in včasih zmanjšani natančnosti v primerjavi s tradicionalnimi pristopi.
Strategije zmanjševanja podatkov
Zasnova, osredotočena na zasebnost, zahteva zbiranje samo podatkov, potrebnih za predvideno funkcionalnost, vendar definiranje "potrebnega" za prilagodljive pogovorne sisteme predstavlja težave:
Kako lahko sistemi vnaprej določijo, kakšen kontekst bo morda potreben za prihodnje interakcije?
Katere osnovne informacije so potrebne za zagotavljanje prilagojenih izkušenj, ki spoštujejo zasebnost?
Kako lahko sistemi uravnotežijo takojšnje potrebe po funkcionalnosti s potencialno uporabnostjo v prihodnosti?
Nekateri pristopi se osredotočajo na časovno omejeno hrambo podatkov, shranjevanje zgodovine interakcij samo za določena obdobja, ki ustrezajo pričakovanim vzorcem uporabe. Drugi poudarjajo uporabniški nadzor, ki posameznikom omogoča, da določijo, katere zgodovinske podatke je treba ohraniti ali pozabiti.
Omejitve anonimizacije
Tradicionalne tehnike anonimizacije se pogosto izkažejo za neustrezne za pogovorne podatke, ki vsebujejo bogate kontekstualne informacije, ki lahko olajšajo ponovno identifikacijo:
Govorni vzorci in izbira besed so lahko zelo prepoznavni
Vprašanja o osebnih okoliščinah lahko razkrijejo določljive podrobnosti, tudi če so odstranjeni podatki, ki omogočajo neposredno identifikacijo
Kumulativni učinek več interakcij lahko ustvari prepoznavne profile tudi iz na videz anonimnih posameznih izmenjav.
Raziskave naprednih tehnik anonimizacije, ki so posebej zasnovane za pogovorno vsebino, se nadaljujejo, vendar popolna anonimizacija ob ohranjanju uporabnosti ostaja nedosegljiv cilj.
Ti tehnični izzivi poudarjajo, zakaj pogovorna umetna inteligenca, ki ohranja zasebnost, zahteva bistveno nove pristope namesto zgolj uporabe tradicionalnih tehnik zasebnosti v obstoječih arhitekturah umetne inteligence. Napredek zahteva poglobljeno sodelovanje med raziskovalci umetne inteligence, strokovnjaki za zasebnost in sistemskimi arhitekti, da bi razvili pristope, ki spoštujejo zasebnost že pri zasnovi, ne pa naknadno.
Več ključnih tehničnih izzivov stoji na presečišču pogovorne umetne inteligence in zasebnosti:
Obdelava v napravi v primerjavi z računalništvom v oblaku
Premik obdelave iz oblaka v napravo (robno računalništvo) lahko bistveno izboljša zasebnost, tako da občutljive podatke ohranja lokalno. Vendar se ta pristop sooča z bistvenimi omejitvami:
Mobilne in domače naprave imajo omejene računalniške vire v primerjavi z infrastrukturo v oblaku
Večji modeli AI morda ne bodo ustrezali potrošniškim napravam
Modeli v napravi lahko zagotovijo manj kakovostne odzive brez dostopa do centraliziranega učenja
Pogoste posodobitve modela lahko porabijo veliko pasovne širine in prostora za shranjevanje
Kljub tem izzivom napredek pri stiskanju modelov in specializirani strojni opremi z umetno inteligenco omogočata, da je obdelava v napravi vedno bolj izvedljiva. Nekateri sistemi zdaj uporabljajo hibridne pristope, ki izvajajo začetno obdelavo lokalno in pošiljajo samo potrebne podatke v oblak.
Strojno učenje, ki varuje zasebnost
Tradicionalni pristopi strojnega učenja so bili osredotočeni na centralizirano zbiranje podatkov, vendar se pojavljajo alternative, osredotočene na zasebnost:
Zvezno učenje omogoča usposabljanje modelov v številnih napravah, medtem ko so osebni podatki lokalni. Z osrednjimi strežniki se delijo samo posodobitve modela (ne uporabniški podatki), kar ščiti zasebnost posameznikov, hkrati pa omogoča izboljšanje sistema.
Diferencialna zasebnost uvaja izračunani šum v nize podatkov ali poizvedbe, da prepreči identifikacijo posameznikov, hkrati pa ohranja statistično veljavnost za usposabljanje in analizo.
Varno večstransko računanje omogoča analizo v več virih podatkov, ne da bi bilo treba kateri koli strani razkriti svoje neobdelane podatke drugim.
Te tehnike obetajo, vendar prinašajo kompromise v računalniški učinkovitosti, kompleksnosti implementacije in včasih zmanjšani natančnosti v primerjavi s tradicionalnimi pristopi.
Strategije zmanjševanja podatkov
Zasnova, osredotočena na zasebnost, zahteva zbiranje samo podatkov, potrebnih za predvideno funkcionalnost, vendar definiranje "potrebnega" za prilagodljive pogovorne sisteme predstavlja težave:
Kako lahko sistemi vnaprej določijo, kakšen kontekst bo morda potreben za prihodnje interakcije?
Katere osnovne informacije so potrebne za zagotavljanje prilagojenih izkušenj, ki spoštujejo zasebnost?
Kako lahko sistemi uravnotežijo takojšnje potrebe po funkcionalnosti s potencialno uporabnostjo v prihodnosti?
Nekateri pristopi se osredotočajo na časovno omejeno hrambo podatkov, shranjevanje zgodovine interakcij samo za določena obdobja, ki ustrezajo pričakovanim vzorcem uporabe. Drugi poudarjajo uporabniški nadzor, ki posameznikom omogoča, da določijo, katere zgodovinske podatke je treba ohraniti ali pozabiti.
Omejitve anonimizacije
Tradicionalne tehnike anonimizacije se pogosto izkažejo za neustrezne za pogovorne podatke, ki vsebujejo bogate kontekstualne informacije, ki lahko olajšajo ponovno identifikacijo:
Govorni vzorci in izbira besed so lahko zelo prepoznavni
Vprašanja o osebnih okoliščinah lahko razkrijejo določljive podrobnosti, tudi če so odstranjeni podatki, ki omogočajo neposredno identifikacijo
Kumulativni učinek več interakcij lahko ustvari prepoznavne profile tudi iz na videz anonimnih posameznih izmenjav.
Raziskave naprednih tehnik anonimizacije, ki so posebej zasnovane za pogovorno vsebino, se nadaljujejo, vendar popolna anonimizacija ob ohranjanju uporabnosti ostaja nedosegljiv cilj.
Ti tehnični izzivi poudarjajo, zakaj pogovorna umetna inteligenca, ki ohranja zasebnost, zahteva bistveno nove pristope namesto zgolj uporabe tradicionalnih tehnik zasebnosti v obstoječih arhitekturah umetne inteligence. Napredek zahteva poglobljeno sodelovanje med raziskovalci umetne inteligence, strokovnjaki za zasebnost in sistemskimi arhitekti, da bi razvili pristope, ki spoštujejo zasebnost že pri zasnovi, ne pa naknadno.
Transparentnost in privolitev: premislek o nadzoru uporabnikov
Pogovorna narava pomočnikov AI ustvarja edinstvene izzive za tradicionalne modele preglednosti in soglasja. Standardni pristopi, kot so dolgotrajni pravilniki o zasebnosti ali enkratne zahteve za soglasje, se v tem kontekstu izkažejo za še posebej nezadostne.
Več dejavnikov otežuje preglednost in soglasje za pogovorne vmesnike:
Model priložnostne interakcije, ki temelji na govoru, ni primeren za podrobne razlage zasebnosti
Uporabniki pogosto ne razlikujejo med različnimi funkcionalnimi domenami, ki imajo lahko različne posledice za zasebnost
Stalno razmerje s pogovorno umetno inteligenco ustvarja več možnih trenutkov privolitve
Sistemi, ki se zavedajo konteksta, lahko zbirajo informacije, ki jih uporabniki niso izrecno nameravali deliti
Integracije tretjih oseb ustvarjajo zapletene tokove podatkov, ki jih je težko jasno sporočiti
Napredna podjetja raziskujejo nove pristope, ki so bolj primerni za te izzive:
Večplastno razkritje
Namesto da bi uporabnike naenkrat preplavili z izčrpnimi informacijami o zasebnosti, večplastno razkritje zagotavlja informacije v prebavljivih segmentih v ustreznih trenutkih:
Začetna nastavitev vključuje osnovne nastavitve zasebnosti
Ob uporabi novih zmožnosti so razložene posledice glede zasebnosti, specifične za posamezne funkcije
Občasne "preveritve" zasebnosti pregledujejo zbiranje in uporabo podatkov
Informacije o zasebnosti so na voljo na zahtevo prek posebnih glasovnih ukazov
Ta pristop priznava, da se razumevanje zasebnosti sčasoma razvije s ponavljajočimi se interakcijami in ne iz enega samega dogodka razkritja.
Kontekstualno soglasje
Če presegamo binarne modele privolitve/odjave, kontekstualno soglasje išče dovoljenje na pomembnih točkah odločanja na uporabniški poti:
Ko bi se zbirala nova vrsta osebnih podatkov
Preden omogočite funkcije, ki pomembno vplivajo na zasebnost
Pri prehodu z lokalne obdelave na obdelavo v oblaku
Preden delite podatke s storitvami tretjih oseb
Pri spreminjanju načina uporabe predhodno zbranih podatkov
Ključnega pomena je, da kontekstualno soglasje zagotavlja dovolj informacij za premišljene odločitve, ne da bi preobremenili uporabnike, in pojasnjuje tako prednosti kot posledice vsake izbire glede zasebnosti.
Interaktivni nadzor zasebnosti
Glasovni vmesniki zahtevajo glasovno dostopne kontrole zasebnosti. Vodilni sistemi razvijajo vmesnike v naravnem jeziku za upravljanje zasebnosti:
"Katere podatke o meni shranjujete?"
"Izbriši mojo zgodovino nakupovanja iz prejšnjega tedna"
"Nehaj shranjevati moje glasovne posnetke"
"Kdo ima dostop do mojih vprašanj o zdravstvenih temah?"
Ti pogovorni kontrolniki zasebnosti naredijo zaščito bolj dostopno kot zakopani meniji nastavitev, čeprav predstavljajo lastne izzive pri oblikovanju pri potrjevanju identitete in namena uporabnika.
Osebe zasebnosti in učenje preferenc
Nekateri sistemi raziskujejo zasebnostne "persone" ali profile, ki združujejo povezane izbire zasebnosti za poenostavitev odločanja. Drugi uporabljajo strojno učenje, da sčasoma razumejo individualne preference glede zasebnosti in predlagajo ustrezne nastavitve na podlagi preteklih odločitev, medtem ko še vedno ohranjajo izrecni nadzor.
Za podjetja in razvijalce je treba za oblikovanje učinkovitih mehanizmov preglednosti in soglasja priznati, da imajo uporabniki različne preference glede zasebnosti in stopnje pismenosti. Najuspešnejši pristopi se prilagajajo tej raznolikosti z zagotavljanjem več poti do razumevanja in nadzora namesto rešitev, ki ustrezajo vsem.
Ker postaja pogovorna umetna inteligenca vse globlje vključena v vsakdanje življenje, ustvarjanje vmesnikov, ki učinkovito sporočajo posledice zasebnosti, ne da bi pri tem motili naravno interakcijo, ostaja stalen izziv pri oblikovanju, a bistvenega pomena za gradnjo zaupanja vrednih sistemov.
Več dejavnikov otežuje preglednost in soglasje za pogovorne vmesnike:
Model priložnostne interakcije, ki temelji na govoru, ni primeren za podrobne razlage zasebnosti
Uporabniki pogosto ne razlikujejo med različnimi funkcionalnimi domenami, ki imajo lahko različne posledice za zasebnost
Stalno razmerje s pogovorno umetno inteligenco ustvarja več možnih trenutkov privolitve
Sistemi, ki se zavedajo konteksta, lahko zbirajo informacije, ki jih uporabniki niso izrecno nameravali deliti
Integracije tretjih oseb ustvarjajo zapletene tokove podatkov, ki jih je težko jasno sporočiti
Napredna podjetja raziskujejo nove pristope, ki so bolj primerni za te izzive:
Večplastno razkritje
Namesto da bi uporabnike naenkrat preplavili z izčrpnimi informacijami o zasebnosti, večplastno razkritje zagotavlja informacije v prebavljivih segmentih v ustreznih trenutkih:
Začetna nastavitev vključuje osnovne nastavitve zasebnosti
Ob uporabi novih zmožnosti so razložene posledice glede zasebnosti, specifične za posamezne funkcije
Občasne "preveritve" zasebnosti pregledujejo zbiranje in uporabo podatkov
Informacije o zasebnosti so na voljo na zahtevo prek posebnih glasovnih ukazov
Ta pristop priznava, da se razumevanje zasebnosti sčasoma razvije s ponavljajočimi se interakcijami in ne iz enega samega dogodka razkritja.
Kontekstualno soglasje
Če presegamo binarne modele privolitve/odjave, kontekstualno soglasje išče dovoljenje na pomembnih točkah odločanja na uporabniški poti:
Ko bi se zbirala nova vrsta osebnih podatkov
Preden omogočite funkcije, ki pomembno vplivajo na zasebnost
Pri prehodu z lokalne obdelave na obdelavo v oblaku
Preden delite podatke s storitvami tretjih oseb
Pri spreminjanju načina uporabe predhodno zbranih podatkov
Ključnega pomena je, da kontekstualno soglasje zagotavlja dovolj informacij za premišljene odločitve, ne da bi preobremenili uporabnike, in pojasnjuje tako prednosti kot posledice vsake izbire glede zasebnosti.
Interaktivni nadzor zasebnosti
Glasovni vmesniki zahtevajo glasovno dostopne kontrole zasebnosti. Vodilni sistemi razvijajo vmesnike v naravnem jeziku za upravljanje zasebnosti:
"Katere podatke o meni shranjujete?"
"Izbriši mojo zgodovino nakupovanja iz prejšnjega tedna"
"Nehaj shranjevati moje glasovne posnetke"
"Kdo ima dostop do mojih vprašanj o zdravstvenih temah?"
Ti pogovorni kontrolniki zasebnosti naredijo zaščito bolj dostopno kot zakopani meniji nastavitev, čeprav predstavljajo lastne izzive pri oblikovanju pri potrjevanju identitete in namena uporabnika.
Osebe zasebnosti in učenje preferenc
Nekateri sistemi raziskujejo zasebnostne "persone" ali profile, ki združujejo povezane izbire zasebnosti za poenostavitev odločanja. Drugi uporabljajo strojno učenje, da sčasoma razumejo individualne preference glede zasebnosti in predlagajo ustrezne nastavitve na podlagi preteklih odločitev, medtem ko še vedno ohranjajo izrecni nadzor.
Za podjetja in razvijalce je treba za oblikovanje učinkovitih mehanizmov preglednosti in soglasja priznati, da imajo uporabniki različne preference glede zasebnosti in stopnje pismenosti. Najuspešnejši pristopi se prilagajajo tej raznolikosti z zagotavljanjem več poti do razumevanja in nadzora namesto rešitev, ki ustrezajo vsem.
Ker postaja pogovorna umetna inteligenca vse globlje vključena v vsakdanje življenje, ustvarjanje vmesnikov, ki učinkovito sporočajo posledice zasebnosti, ne da bi pri tem motili naravno interakcijo, ostaja stalen izziv pri oblikovanju, a bistvenega pomena za gradnjo zaupanja vrednih sistemov.
Testirajte AI na VAŠI spletni strani v 60 sekundah
Poglejte, kako naša umetna inteligenca takoj analizira vašo spletno stran in ustvari personaliziranega chatbota - brez registracije. Samo vnesite svoj URL in opazujte, kako deluje!
Pripravljeno v 60 sekundah
Brez potrebe po kodiranju
100% varno
Posebni premisleki za ranljive skupine
Pogovorna umetna inteligenca vzbuja večje pomisleke glede zasebnosti pri ranljivih skupinah, katerih specifičnih potreb morda ne bodo ustrezno obravnavali splošni pristopi k zasebnosti. Te skupine vključujejo otroke, starejše odrasle, posameznike s kognitivnimi motnjami in tiste z omejeno tehnološko pismenostjo.
Otroci in zasebnost
Otroci predstavljajo populacijo, ki vzbuja posebno skrb, saj morda ne razumejo posledic za zasebnost, vendar vedno pogosteje komunicirajo s pogovornimi vmesniki:
Mnogim otrokom primanjkuje razvojne sposobnosti za sprejemanje premišljenih odločitev o zasebnosti
Otroci lahko bolj svobodno delijo informacije v pogovoru, ne da bi razumeli morebitne posledice
Mladi uporabniki morda ne razlikujejo med pogovorom z umetno inteligenco in zaupanja vrednim človeškim zaupnikom
Podatki, zbrani v otroštvu, bi lahko posameznike spremljali desetletja
Regulativni okviri, kot je COPPA v ZDA, in posebne določbe GDPR za otroke vzpostavljajo osnovno zaščito, vendar ostajajo izzivi pri izvajanju. Tehnologija za prepoznavanje glasu ima lahko težave pri zanesljivi identifikaciji uporabnikov otrok, kar otežuje starostno primerne ukrepe glede zasebnosti. Sistemi, zasnovani predvsem za odrasle, morda ne bodo ustrezno razložili konceptov zasebnosti v otrokom dostopnem jeziku.
Razvijalci, ki ustvarjajo pogovorno umetno inteligenco ali funkcije, osredotočene na otroke, morajo upoštevati specializirane pristope, vključno z:
Privzete nastavitve visoke zasebnosti s starševskim nadzorom za prilagajanje
Starosti primerne razlage zbiranja podatkov s konkretnimi primeri
Omejena obdobja hrambe podatkov za otroke
Omejena uporaba podatkov, ki prepoveduje profiliranje ali vedenjsko ciljanje
Jasni indikatorji, kdaj bodo informacije posredovane staršem
Starejši odrasli in vidiki dostopnosti
Starejši odrasli in posamezniki s posebnimi potrebami imajo lahko pomembne koristi od pogovornih vmesnikov, ki pogosto zagotavljajo bolj dostopne modele interakcije kot tradicionalni računalniški vmesniki. Vendar se lahko soočijo tudi z različnimi izzivi glede zasebnosti:
Omejeno poznavanje tehnoloških konceptov lahko vpliva na razumevanje zasebnosti
Kognitivne okvare lahko vplivajo na sposobnost sprejemanja zapletenih odločitev glede zasebnosti
Odvisnost od podporne tehnologije lahko zmanjša praktično zmožnost zavrnitve pogojev zasebnosti
Uporaba v zvezi z zdravjem lahko vključuje posebej občutljive podatke
Skupne naprave v nastavitvah oskrbe ustvarjajo zapletene scenarije privolitve
Odgovorno načrtovanje za te populacije zahteva premišljeno prilagoditev brez ogrožanja delovanja. Pristopi vključujejo:
Večmodalne razlage zasebnosti, ki informacije predstavljajo v različnih formatih
Poenostavljene izbire glede zasebnosti so osredotočene na praktične učinke in ne na tehnične podrobnosti
Imenovani zaupni predstavniki za odločitve o zasebnosti, kadar je to primerno
Izboljšana varnost za funkcije, povezane z zdravjem in nego
Jasno ločevanje med splošno pomočjo in zdravniškim nasvetom
Digitalna pismenost in razkorak v zasebnosti
Med starostnimi skupinami različne ravni digitalne in zasebnostne pismenosti ustvarjajo tisto, kar raziskovalci imenujejo "razkorak v zasebnosti" – kjer lahko tisti z večjim razumevanjem bolje zaščitijo svoje podatke, drugi pa ostajajo bolj ranljivi. Čeprav so pogovorni vmesniki potencialno bolj intuitivni od tradicionalnega računalništva, še vedno vključujejo zapletene implikacije glede zasebnosti, ki morda niso očitne vsem uporabnikom.
Premostitev te ločnice zahteva pristope, ki omogočajo dostop do zasebnosti brez predpostavke tehničnega znanja:
Pojasnila glede zasebnosti, ki se osredotočajo na konkretne rezultate in ne na tehnične mehanizme
Primeri, ki ponazarjajo morebitna tveganja za zasebnost v primerljivih scenarijih
Postopno razkritje, ki uvaja koncepte, ko postanejo relevantni
Alternative informacijam o zasebnosti, ki vsebujejo veliko besedila, vključno z vizualnimi in zvočnimi oblikami
Navsezadnje je za ustvarjanje resnično vključujoče pogovorne umetne inteligence treba priznati, da se potrebe po zasebnosti in razumevanje med populacijami zelo razlikujejo. Pristopi, ki ustrezajo vsem, ranljive uporabnike neizogibno puščajo z neustrezno zaščito ali so izključeni iz koristnih tehnologij. Najbolj etična izvajanja priznavajo te razlike in zagotavljajo ustrezne prilagoditve, hkrati pa ohranjajo spoštovanje avtonomije posameznika.
Otroci in zasebnost
Otroci predstavljajo populacijo, ki vzbuja posebno skrb, saj morda ne razumejo posledic za zasebnost, vendar vedno pogosteje komunicirajo s pogovornimi vmesniki:
Mnogim otrokom primanjkuje razvojne sposobnosti za sprejemanje premišljenih odločitev o zasebnosti
Otroci lahko bolj svobodno delijo informacije v pogovoru, ne da bi razumeli morebitne posledice
Mladi uporabniki morda ne razlikujejo med pogovorom z umetno inteligenco in zaupanja vrednim človeškim zaupnikom
Podatki, zbrani v otroštvu, bi lahko posameznike spremljali desetletja
Regulativni okviri, kot je COPPA v ZDA, in posebne določbe GDPR za otroke vzpostavljajo osnovno zaščito, vendar ostajajo izzivi pri izvajanju. Tehnologija za prepoznavanje glasu ima lahko težave pri zanesljivi identifikaciji uporabnikov otrok, kar otežuje starostno primerne ukrepe glede zasebnosti. Sistemi, zasnovani predvsem za odrasle, morda ne bodo ustrezno razložili konceptov zasebnosti v otrokom dostopnem jeziku.
Razvijalci, ki ustvarjajo pogovorno umetno inteligenco ali funkcije, osredotočene na otroke, morajo upoštevati specializirane pristope, vključno z:
Privzete nastavitve visoke zasebnosti s starševskim nadzorom za prilagajanje
Starosti primerne razlage zbiranja podatkov s konkretnimi primeri
Omejena obdobja hrambe podatkov za otroke
Omejena uporaba podatkov, ki prepoveduje profiliranje ali vedenjsko ciljanje
Jasni indikatorji, kdaj bodo informacije posredovane staršem
Starejši odrasli in vidiki dostopnosti
Starejši odrasli in posamezniki s posebnimi potrebami imajo lahko pomembne koristi od pogovornih vmesnikov, ki pogosto zagotavljajo bolj dostopne modele interakcije kot tradicionalni računalniški vmesniki. Vendar se lahko soočijo tudi z različnimi izzivi glede zasebnosti:
Omejeno poznavanje tehnoloških konceptov lahko vpliva na razumevanje zasebnosti
Kognitivne okvare lahko vplivajo na sposobnost sprejemanja zapletenih odločitev glede zasebnosti
Odvisnost od podporne tehnologije lahko zmanjša praktično zmožnost zavrnitve pogojev zasebnosti
Uporaba v zvezi z zdravjem lahko vključuje posebej občutljive podatke
Skupne naprave v nastavitvah oskrbe ustvarjajo zapletene scenarije privolitve
Odgovorno načrtovanje za te populacije zahteva premišljeno prilagoditev brez ogrožanja delovanja. Pristopi vključujejo:
Večmodalne razlage zasebnosti, ki informacije predstavljajo v različnih formatih
Poenostavljene izbire glede zasebnosti so osredotočene na praktične učinke in ne na tehnične podrobnosti
Imenovani zaupni predstavniki za odločitve o zasebnosti, kadar je to primerno
Izboljšana varnost za funkcije, povezane z zdravjem in nego
Jasno ločevanje med splošno pomočjo in zdravniškim nasvetom
Digitalna pismenost in razkorak v zasebnosti
Med starostnimi skupinami različne ravni digitalne in zasebnostne pismenosti ustvarjajo tisto, kar raziskovalci imenujejo "razkorak v zasebnosti" – kjer lahko tisti z večjim razumevanjem bolje zaščitijo svoje podatke, drugi pa ostajajo bolj ranljivi. Čeprav so pogovorni vmesniki potencialno bolj intuitivni od tradicionalnega računalništva, še vedno vključujejo zapletene implikacije glede zasebnosti, ki morda niso očitne vsem uporabnikom.
Premostitev te ločnice zahteva pristope, ki omogočajo dostop do zasebnosti brez predpostavke tehničnega znanja:
Pojasnila glede zasebnosti, ki se osredotočajo na konkretne rezultate in ne na tehnične mehanizme
Primeri, ki ponazarjajo morebitna tveganja za zasebnost v primerljivih scenarijih
Postopno razkritje, ki uvaja koncepte, ko postanejo relevantni
Alternative informacijam o zasebnosti, ki vsebujejo veliko besedila, vključno z vizualnimi in zvočnimi oblikami
Navsezadnje je za ustvarjanje resnično vključujoče pogovorne umetne inteligence treba priznati, da se potrebe po zasebnosti in razumevanje med populacijami zelo razlikujejo. Pristopi, ki ustrezajo vsem, ranljive uporabnike neizogibno puščajo z neustrezno zaščito ali so izključeni iz koristnih tehnologij. Najbolj etična izvajanja priznavajo te razlike in zagotavljajo ustrezne prilagoditve, hkrati pa ohranjajo spoštovanje avtonomije posameznika.
Poslovni premisleki: ravnovesje med inovativnostjo in odgovornostjo
Za podjetja, ki razvijajo ali uvajajo pogovorno umetno inteligenco, krmarjenje z izzivi glede zasebnosti vključuje kompleksne strateške odločitve, ki usklajujejo poslovne cilje z etično odgovornostjo in regulativnimi zahtevami.
Poslovni primer oblikovanja, osredotočenega na zasebnost
Čeprav se na prvi pogled morda zdi, da zaščita zasebnosti omejuje poslovne priložnosti, napredno misleča podjetja vedno bolj priznavajo poslovno vrednost močnih praks zasebnosti:
Zaupanje kot konkurenčna prednost – Ko se ozaveščenost o zasebnosti povečuje, postajajo zanesljive podatkovne prakse pomembna razlika. Raziskave dosledno kažejo, da imajo potrošniki raje storitve, za katere verjamejo, da bodo zaščitile njihove osebne podatke.
Učinkovitost skladnosti s predpisi – Vgradnja zasebnosti v pogovorno umetno inteligenco od začetka zmanjša drago naknadno opremljanje z razvojem predpisov. Ta pristop "privacy by design" predstavlja znatne dolgoročne prihranke v primerjavi z obravnavanjem zasebnosti kot naknadne zamisli.
Zmanjšanje tveganja – Kršitve podatkov in škandali glede zasebnosti povzročajo znatne stroške, od regulativnih kazni do škode za ugled. Zasnova, osredotočena na zasebnost, zmanjšuje ta tveganja z minimizacijo podatkov in ustreznimi varnostnimi ukrepi.
Dostop do trga – Močne prakse varovanja zasebnosti omogočajo delovanje v regijah s strogimi predpisi, širitev potencialnih trgov brez potrebe po več različicah izdelkov.
Ti dejavniki ustvarjajo prepričljive poslovne spodbude za naložbe v zasebnost, ki presegajo zgolj skladnost, zlasti za pogovorno umetno inteligenco, kjer zaupanje neposredno vpliva na pripravljenost uporabnikov za sodelovanje s tehnologijo.
Strateški pristopi k zbiranju podatkov
Podjetja se morajo premišljeno odločiti, katere podatke zbirajo njihovi pogovorni sistemi in kako se uporabljajo:
Funkcionalni minimalizem – Zbiranje samo podatkov, ki so neposredno potrebni za zahtevano funkcionalnost, z jasnimi mejami med osnovnim in neobveznim zbiranjem podatkov.
Specifičnost namena – opredelitev ozkih, eksplicitnih namenov za uporabo podatkov namesto širokega, odprtega zbiranja, ki bi lahko služilo prihodnjim nedoločenim potrebam.
Razlikovanje preglednosti – jasno razlikovanje med podatki, ki se uporabljajo za takojšnjo funkcionalnost, in izboljšavo sistema, kar uporabnikom omogoča ločen nadzor nad temi različnimi uporabami.
Stopnje zasebnosti – ponujajo možnosti storitev z različnimi kompromisi med zasebnostjo in funkcionalnostjo, kar uporabnikom omogoča izbiro želenega ravnovesja.
Ti pristopi pomagajo podjetjem, da se izognejo miselnosti "zberi vse, kar je mogoče", ki ustvarja tako tveganja glede zasebnosti kot potencialno regulativno izpostavljenost.
Uravnoteženje integracije prve in tretje osebe
Pogovorne platforme pogosto služijo kot prehodi v širše storitvene ekosisteme, kar odpira vprašanja o izmenjavi in integraciji podatkov:
Kako je treba upravljati soglasje uporabnikov, ko pogovori zajemajo več storitev?
Kdo je odgovoren za zaščito zasebnosti v integriranih izkušnjah?
Kako je mogoče dosledno vzdrževati pričakovanja glede zasebnosti v celotnem ekosistemu?
Katere podatke o zasebnosti naj si delijo integracijski partnerji?
Vodilna podjetja te izzive rešujejo z jasnimi zahtevami za partnerje, standardiziranimi vmesniki za zasebnost in preglednim razkritjem podatkovnih tokov med storitvami. Nekateri izvajajo "zasebne oznake hranilne vrednosti", ki hitro sporočijo bistvene podatke o zasebnosti, preden uporabniki prek svojih pogovornih platform sodelujejo s storitvami tretjih oseb.
Ustvarjanje trajnostnega upravljanja podatkov
Za učinkovito varstvo zasebnosti so potrebne trdne strukture upravljanja, ki usklajujejo potrebe po inovacijah z odgovornostmi glede zasebnosti:
Medfunkcionalne skupine za zasebnost, ki vključujejo vidike izdelkov, inženiringa, prava in etike
Ocene vpliva na zasebnost, izvedene na začetku razvoja izdelka
Redne revizije zasebnosti za preverjanje skladnosti z navedenimi politikami
Jasne strukture odgovornosti, ki določajo odgovornosti glede zasebnosti v celotni organizaciji
Odbori za etiko obravnavajo nova vprašanja zasebnosti, ki se pojavijo v pogovornem kontekstu
Ti mehanizmi upravljanja pomagajo zagotoviti, da so pomisleki glede zasebnosti vključeni v celoten razvojni proces, namesto da bi se obravnavali le na stopnjah končnega pregleda, ko spremembe postanejo drage.
Za podjetja, ki vlagajo v pogovorno umetno inteligenco, zasebnosti ne bi smeli obravnavati kot breme skladnosti, temveč kot temeljni element trajnostnih inovacij. Podjetja, ki vzpostavijo zaupanja vredne prakse varovanja zasebnosti, ustvarjajo pogoje za širše sprejemanje in sprejemanje svojih pogovornih tehnologij, kar na koncu omogoča dragocenejše odnose z uporabniki.
Poslovni primer oblikovanja, osredotočenega na zasebnost
Čeprav se na prvi pogled morda zdi, da zaščita zasebnosti omejuje poslovne priložnosti, napredno misleča podjetja vedno bolj priznavajo poslovno vrednost močnih praks zasebnosti:
Zaupanje kot konkurenčna prednost – Ko se ozaveščenost o zasebnosti povečuje, postajajo zanesljive podatkovne prakse pomembna razlika. Raziskave dosledno kažejo, da imajo potrošniki raje storitve, za katere verjamejo, da bodo zaščitile njihove osebne podatke.
Učinkovitost skladnosti s predpisi – Vgradnja zasebnosti v pogovorno umetno inteligenco od začetka zmanjša drago naknadno opremljanje z razvojem predpisov. Ta pristop "privacy by design" predstavlja znatne dolgoročne prihranke v primerjavi z obravnavanjem zasebnosti kot naknadne zamisli.
Zmanjšanje tveganja – Kršitve podatkov in škandali glede zasebnosti povzročajo znatne stroške, od regulativnih kazni do škode za ugled. Zasnova, osredotočena na zasebnost, zmanjšuje ta tveganja z minimizacijo podatkov in ustreznimi varnostnimi ukrepi.
Dostop do trga – Močne prakse varovanja zasebnosti omogočajo delovanje v regijah s strogimi predpisi, širitev potencialnih trgov brez potrebe po več različicah izdelkov.
Ti dejavniki ustvarjajo prepričljive poslovne spodbude za naložbe v zasebnost, ki presegajo zgolj skladnost, zlasti za pogovorno umetno inteligenco, kjer zaupanje neposredno vpliva na pripravljenost uporabnikov za sodelovanje s tehnologijo.
Strateški pristopi k zbiranju podatkov
Podjetja se morajo premišljeno odločiti, katere podatke zbirajo njihovi pogovorni sistemi in kako se uporabljajo:
Funkcionalni minimalizem – Zbiranje samo podatkov, ki so neposredno potrebni za zahtevano funkcionalnost, z jasnimi mejami med osnovnim in neobveznim zbiranjem podatkov.
Specifičnost namena – opredelitev ozkih, eksplicitnih namenov za uporabo podatkov namesto širokega, odprtega zbiranja, ki bi lahko služilo prihodnjim nedoločenim potrebam.
Razlikovanje preglednosti – jasno razlikovanje med podatki, ki se uporabljajo za takojšnjo funkcionalnost, in izboljšavo sistema, kar uporabnikom omogoča ločen nadzor nad temi različnimi uporabami.
Stopnje zasebnosti – ponujajo možnosti storitev z različnimi kompromisi med zasebnostjo in funkcionalnostjo, kar uporabnikom omogoča izbiro želenega ravnovesja.
Ti pristopi pomagajo podjetjem, da se izognejo miselnosti "zberi vse, kar je mogoče", ki ustvarja tako tveganja glede zasebnosti kot potencialno regulativno izpostavljenost.
Uravnoteženje integracije prve in tretje osebe
Pogovorne platforme pogosto služijo kot prehodi v širše storitvene ekosisteme, kar odpira vprašanja o izmenjavi in integraciji podatkov:
Kako je treba upravljati soglasje uporabnikov, ko pogovori zajemajo več storitev?
Kdo je odgovoren za zaščito zasebnosti v integriranih izkušnjah?
Kako je mogoče dosledno vzdrževati pričakovanja glede zasebnosti v celotnem ekosistemu?
Katere podatke o zasebnosti naj si delijo integracijski partnerji?
Vodilna podjetja te izzive rešujejo z jasnimi zahtevami za partnerje, standardiziranimi vmesniki za zasebnost in preglednim razkritjem podatkovnih tokov med storitvami. Nekateri izvajajo "zasebne oznake hranilne vrednosti", ki hitro sporočijo bistvene podatke o zasebnosti, preden uporabniki prek svojih pogovornih platform sodelujejo s storitvami tretjih oseb.
Ustvarjanje trajnostnega upravljanja podatkov
Za učinkovito varstvo zasebnosti so potrebne trdne strukture upravljanja, ki usklajujejo potrebe po inovacijah z odgovornostmi glede zasebnosti:
Medfunkcionalne skupine za zasebnost, ki vključujejo vidike izdelkov, inženiringa, prava in etike
Ocene vpliva na zasebnost, izvedene na začetku razvoja izdelka
Redne revizije zasebnosti za preverjanje skladnosti z navedenimi politikami
Jasne strukture odgovornosti, ki določajo odgovornosti glede zasebnosti v celotni organizaciji
Odbori za etiko obravnavajo nova vprašanja zasebnosti, ki se pojavijo v pogovornem kontekstu
Ti mehanizmi upravljanja pomagajo zagotoviti, da so pomisleki glede zasebnosti vključeni v celoten razvojni proces, namesto da bi se obravnavali le na stopnjah končnega pregleda, ko spremembe postanejo drage.
Za podjetja, ki vlagajo v pogovorno umetno inteligenco, zasebnosti ne bi smeli obravnavati kot breme skladnosti, temveč kot temeljni element trajnostnih inovacij. Podjetja, ki vzpostavijo zaupanja vredne prakse varovanja zasebnosti, ustvarjajo pogoje za širše sprejemanje in sprejemanje svojih pogovornih tehnologij, kar na koncu omogoča dragocenejše odnose z uporabniki.
Izobraževanje in opolnomočenje uporabnikov: onkraj pravilnikov o zasebnosti
Za ustvarjanje pogovorne umetne inteligence, ki resnično spoštuje zasebnost, je treba preseči tradicionalna obvestila o zasebnosti ter aktivno izobraževati in opolnomočiti uporabnike, da se ozaveščeno odločajo o svojih podatkih.
Omejitve tradicionalne komunikacije o zasebnosti
Standardni pristopi k komunikaciji o zasebnosti še posebej niso dovolj za pogovorne vmesnike:
Politike zasebnosti se redko berejo in so pogosto napisane v zapletenem pravnem jeziku
Tradicionalni vmesniki za upravljanje zasebnosti se ne prenašajo dobro na glasovne interakcije
Enkratna privolitev ne obravnava stalne, razvijajoče se narave pogovornih odnosov
Tehnična pojasnila o zasebnosti pogosto ne sporočajo praktičnih posledic za uporabnike
Te omejitve ustvarjajo situacijo, v kateri je mogoče doseči formalno skladnost (uporabniki so se "strinjali" s pogoji) brez smiselne informirane privolitve. Uporabniki morda ne razumejo, kateri podatki se zbirajo, kako se uporabljajo ali kakšen nadzor imajo nad svojimi informacijami.
Ustvarjanje smiselne pismenosti o zasebnosti
Učinkovitejši pristopi se osredotočajo na ustvarjanje pristnega razumevanja zasebnosti prek:
Pravočasno izobraževanje, ki zagotavlja ustrezne informacije o zasebnosti v ključnih trenutkih in ne vse naenkrat
Razlage v preprostem jeziku, ki se osredotočajo na praktične rezultate in ne na tehnične mehanizme
Konkretni primeri, ki ponazarjajo, kako se lahko uporabljajo podatki, in možne posledice za zasebnost
Interaktivne predstavitve, ki naredijo koncepte zasebnosti oprijemljive in ne abstraktne
Kontekstualni opomniki o tem, kateri podatki se zbirajo med različnimi vrstami interakcij
Ti pristopi priznavajo, da se pismenost o zasebnosti razvija postopoma s ponavljajočo se izpostavljenostjo in praktičnimi izkušnjami, ne z enkratnimi odlagališči informacij.
Projektiranje za agencijo in nadzor
Poleg izobraževanja uporabniki potrebujejo dejanski nadzor nad svojimi informacijami. Učinkoviti pristopi vključujejo:
Zdrobljena dovoljenja, ki uporabnikom omogočajo odobritev določenih uporab namesto soglasja vse ali nič
Nadzorne plošče zasebnosti zagotavljajo jasno vizualizacijo podatkov, ki so bili zbrani
Preproste možnosti brisanja za odstranjevanje zgodovinskih podatkov
Vpogled v uporabo, ki prikazuje, kako osebni podatki vplivajo na vedenje sistema
Bližnjice do zasebnosti za hitro prilagajanje pogostih nastavitev
Redne prijave zasebnosti, ki zahtevajo pregled trenutnih nastavitev in zbiranja podatkov
Bistveno je, da morajo biti ti kontrolniki lahko dostopni prek samega pogovornega vmesnika, ne pa zakopani v ločenih spletnih mestih ali aplikacijah, ki ustvarjajo trenja za uporabnike, ki so najprej glasovni.
Standardi skupnosti in družbene norme
Ker pogovorna umetna inteligenca postaja vse bolj prodorna, igrajo standardi skupnosti in družbene norme vse pomembnejšo vlogo pri oblikovanju pričakovanj glede zasebnosti. Podjetja lahko prispevajo k razvoju zdravih norm z:
Omogočanje izobraževanja o zasebnosti med uporabniki prek forumov skupnosti in izmenjave znanja
Izpostavljanje najboljših praks glede zasebnosti in prepoznavanje uporabnikov, ki jih uporabljajo
Ustvarjanje preglednosti okoli skupnih izbir glede zasebnosti, ki uporabnikom pomaga razumeti norme skupnosti
Vključevanje uporabnikov v razvoj funkcij zasebnosti prek povratnih informacij in sooblikovanja
Ti pristopi priznavajo, da zasebnost ni zgolj skrb posameznika, temveč družbeni konstrukt, ki se razvija s kolektivnim razumevanjem in prakso.
Da lahko pogovorna umetna inteligenca doseže svoj polni potencial ob spoštovanju individualnih pravic, morajo uporabniki postati obveščeni udeleženci in ne pasivni subjekti zbiranja podatkov. To zahteva trajno vlaganje v izobraževanje in opolnomočenje namesto minimalne skladnosti z razkritjem. Podjetja, ki vodijo na tem področju, krepijo odnose z uporabniki, hkrati pa prispevajo k bolj zdravemu splošnemu ekosistemu za pogovorno tehnologijo.
Omejitve tradicionalne komunikacije o zasebnosti
Standardni pristopi k komunikaciji o zasebnosti še posebej niso dovolj za pogovorne vmesnike:
Politike zasebnosti se redko berejo in so pogosto napisane v zapletenem pravnem jeziku
Tradicionalni vmesniki za upravljanje zasebnosti se ne prenašajo dobro na glasovne interakcije
Enkratna privolitev ne obravnava stalne, razvijajoče se narave pogovornih odnosov
Tehnična pojasnila o zasebnosti pogosto ne sporočajo praktičnih posledic za uporabnike
Te omejitve ustvarjajo situacijo, v kateri je mogoče doseči formalno skladnost (uporabniki so se "strinjali" s pogoji) brez smiselne informirane privolitve. Uporabniki morda ne razumejo, kateri podatki se zbirajo, kako se uporabljajo ali kakšen nadzor imajo nad svojimi informacijami.
Ustvarjanje smiselne pismenosti o zasebnosti
Učinkovitejši pristopi se osredotočajo na ustvarjanje pristnega razumevanja zasebnosti prek:
Pravočasno izobraževanje, ki zagotavlja ustrezne informacije o zasebnosti v ključnih trenutkih in ne vse naenkrat
Razlage v preprostem jeziku, ki se osredotočajo na praktične rezultate in ne na tehnične mehanizme
Konkretni primeri, ki ponazarjajo, kako se lahko uporabljajo podatki, in možne posledice za zasebnost
Interaktivne predstavitve, ki naredijo koncepte zasebnosti oprijemljive in ne abstraktne
Kontekstualni opomniki o tem, kateri podatki se zbirajo med različnimi vrstami interakcij
Ti pristopi priznavajo, da se pismenost o zasebnosti razvija postopoma s ponavljajočo se izpostavljenostjo in praktičnimi izkušnjami, ne z enkratnimi odlagališči informacij.
Projektiranje za agencijo in nadzor
Poleg izobraževanja uporabniki potrebujejo dejanski nadzor nad svojimi informacijami. Učinkoviti pristopi vključujejo:
Zdrobljena dovoljenja, ki uporabnikom omogočajo odobritev določenih uporab namesto soglasja vse ali nič
Nadzorne plošče zasebnosti zagotavljajo jasno vizualizacijo podatkov, ki so bili zbrani
Preproste možnosti brisanja za odstranjevanje zgodovinskih podatkov
Vpogled v uporabo, ki prikazuje, kako osebni podatki vplivajo na vedenje sistema
Bližnjice do zasebnosti za hitro prilagajanje pogostih nastavitev
Redne prijave zasebnosti, ki zahtevajo pregled trenutnih nastavitev in zbiranja podatkov
Bistveno je, da morajo biti ti kontrolniki lahko dostopni prek samega pogovornega vmesnika, ne pa zakopani v ločenih spletnih mestih ali aplikacijah, ki ustvarjajo trenja za uporabnike, ki so najprej glasovni.
Standardi skupnosti in družbene norme
Ker pogovorna umetna inteligenca postaja vse bolj prodorna, igrajo standardi skupnosti in družbene norme vse pomembnejšo vlogo pri oblikovanju pričakovanj glede zasebnosti. Podjetja lahko prispevajo k razvoju zdravih norm z:
Omogočanje izobraževanja o zasebnosti med uporabniki prek forumov skupnosti in izmenjave znanja
Izpostavljanje najboljših praks glede zasebnosti in prepoznavanje uporabnikov, ki jih uporabljajo
Ustvarjanje preglednosti okoli skupnih izbir glede zasebnosti, ki uporabnikom pomaga razumeti norme skupnosti
Vključevanje uporabnikov v razvoj funkcij zasebnosti prek povratnih informacij in sooblikovanja
Ti pristopi priznavajo, da zasebnost ni zgolj skrb posameznika, temveč družbeni konstrukt, ki se razvija s kolektivnim razumevanjem in prakso.
Da lahko pogovorna umetna inteligenca doseže svoj polni potencial ob spoštovanju individualnih pravic, morajo uporabniki postati obveščeni udeleženci in ne pasivni subjekti zbiranja podatkov. To zahteva trajno vlaganje v izobraževanje in opolnomočenje namesto minimalne skladnosti z razkritjem. Podjetja, ki vodijo na tem področju, krepijo odnose z uporabniki, hkrati pa prispevajo k bolj zdravemu splošnemu ekosistemu za pogovorno tehnologijo.
Nastajajoče rešitve in najboljše prakse
Ker se zavedanje o izzivih zasebnosti umetne inteligence pri pogovorih povečuje, se pojavljajo inovativni pristopi za reševanje teh vprašanj in hkrati ohranjajo uporabno funkcionalnost.
Tehnologije za izboljšanje zasebnosti za pogovorno umetno inteligenco
Tehnične inovacije, ki se posebej osredotočajo na zasebnost v pogovornem kontekstu, vključujejo:
Lokalne procesne enklave, ki izvajajo občutljive izračune na napravi v varnih okoljih, izoliranih od drugih aplikacij
Homomorfne tehnike šifriranja, ki omogočajo obdelavo šifriranih podatkov brez dešifriranja, kar omogoča analizo, ki ohranja zasebnost
Sintetični podatki o usposabljanju, ustvarjeni za ohranjanje statističnih lastnosti resničnih pogovorov brez izpostavljanja dejanskih uporabniških interakcij
Transkripcija z ohranjanjem zasebnosti, ki lokalno pretvori govor v besedilo, preden pošlje minimizirane besedilne podatke v obdelavo
Izvedbe zveznega učenja, posebej optimizirane za porazdeljeno naravo pogovornih naprav
Te tehnologije so na različnih stopnjah zrelosti, nekatere se že pojavljajo v komercialnih izdelkih, druge pa ostajajo predvsem v raziskovalnih fazah.
Industrijski standardi in okviri
Industrija pogovorne umetne inteligence razvija skupne standarde in okvire za vzpostavitev doslednih pristopov k zasebnosti:
Voice Privacy Alliance je predlagal standardiziran nadzor zasebnosti in formate razkritja za glasovne pomočnike
IEEE ima delovne skupine, ki razvijajo tehnične standarde za zasebnost v govorjenih vmesnikih
Open Voice Network ustvarja standarde interoperabilnosti, ki vključujejo zahteve glede zasebnosti
Različna industrijska združenja so objavila najboljše prakse glede zasebnosti, specifične za pogovorne kontekste
Ta skupna prizadevanja so namenjena vzpostavitvi osnovnih pričakovanj glede zasebnosti, ki poenostavljajo skladnost za razvijalce, hkrati pa zagotavljajo dosledne uporabniške izkušnje na vseh platformah.
Oblikovalski vzorci za pogovorno UX, ki spoštuje zasebnost
Oblikovalci uporabniške izkušnje razvijajo posebne vzorce za ravnanje z zasebnostjo v pogovornih vmesnikih:
Postopno razkritje zasebnosti, ki uvaja informacije v obvladljive segmente
Indikatorji zasebnosti okolja, ki uporabljajo subtilne zvočne ali vizualne namige, ki kažejo, kdaj sistemi poslušajo ali obdelujejo
Koreografija soglasja, ki oblikuje naravne zahteve za dovoljenja, ki ne motijo toka pogovora
Privzete nastavitve za ohranjanje zasebnosti, ki se začnejo z minimalnim zbiranjem podatkov in se razširijo le z izrecno odobritvijo uporabnika
Pozabljanje mehanizmov, zaradi katerih sta potek in brisanje podatkov sestavni del modela interakcije
Namen teh vzorcev načrtovanja je, da vidiki zasebnosti postanejo integrirani del pogovorne izkušnje in ne ločena plast zahtev glede skladnosti.
Najboljše organizacijske prakse
Organizacije, ki so vodilne na področju pogovorne umetne inteligence, ki spoštuje zasebnost, običajno izvajajo več ključnih praks:
Zagovorniki zasebnosti, vključeni v razvojne ekipe, ne le v pravne oddelke
Redne ocene tveganja zasebnosti v celotnem življenjskem ciklu razvoja
Uporabniško testiranje, osredotočeno na zasebnost, ki izrecno ocenjuje razumevanje in nadzor zasebnosti
Poročila o preglednosti, ki zagotavljajo vpogled v podatkovne prakse in vladne zahteve po informacijah
Zunanje revizije zasebnosti, ki potrjujejo, da se dejanske prakse ujemajo z navedenimi politikami
Programi nagrad za napake v zasebnosti, ki spodbujajo odkrivanje ranljivosti zasebnosti
Ti organizacijski pristopi zagotavljajo, da ostajajo vidiki zasebnosti osrednji v celotnem razvoju izdelka, namesto da postanejo naknadna misel med pravnim pregledom.
Za razvijalce in podjetja, ki delajo v tem prostoru, te nastajajoče rešitve zagotavljajo dragoceno usmeritev za ustvarjanje pogovorne umetne inteligence, ki spoštuje zasebnost in hkrati zagotavlja prepričljive uporabniške izkušnje. Čeprav noben posamezen pristop ne reši vseh izzivov glede zasebnosti, lahko premišljena kombinacija tehničnih, oblikovalskih in organizacijskih praks bistveno izboljša rezultate glede zasebnosti.
Tehnologije za izboljšanje zasebnosti za pogovorno umetno inteligenco
Tehnične inovacije, ki se posebej osredotočajo na zasebnost v pogovornem kontekstu, vključujejo:
Lokalne procesne enklave, ki izvajajo občutljive izračune na napravi v varnih okoljih, izoliranih od drugih aplikacij
Homomorfne tehnike šifriranja, ki omogočajo obdelavo šifriranih podatkov brez dešifriranja, kar omogoča analizo, ki ohranja zasebnost
Sintetični podatki o usposabljanju, ustvarjeni za ohranjanje statističnih lastnosti resničnih pogovorov brez izpostavljanja dejanskih uporabniških interakcij
Transkripcija z ohranjanjem zasebnosti, ki lokalno pretvori govor v besedilo, preden pošlje minimizirane besedilne podatke v obdelavo
Izvedbe zveznega učenja, posebej optimizirane za porazdeljeno naravo pogovornih naprav
Te tehnologije so na različnih stopnjah zrelosti, nekatere se že pojavljajo v komercialnih izdelkih, druge pa ostajajo predvsem v raziskovalnih fazah.
Industrijski standardi in okviri
Industrija pogovorne umetne inteligence razvija skupne standarde in okvire za vzpostavitev doslednih pristopov k zasebnosti:
Voice Privacy Alliance je predlagal standardiziran nadzor zasebnosti in formate razkritja za glasovne pomočnike
IEEE ima delovne skupine, ki razvijajo tehnične standarde za zasebnost v govorjenih vmesnikih
Open Voice Network ustvarja standarde interoperabilnosti, ki vključujejo zahteve glede zasebnosti
Različna industrijska združenja so objavila najboljše prakse glede zasebnosti, specifične za pogovorne kontekste
Ta skupna prizadevanja so namenjena vzpostavitvi osnovnih pričakovanj glede zasebnosti, ki poenostavljajo skladnost za razvijalce, hkrati pa zagotavljajo dosledne uporabniške izkušnje na vseh platformah.
Oblikovalski vzorci za pogovorno UX, ki spoštuje zasebnost
Oblikovalci uporabniške izkušnje razvijajo posebne vzorce za ravnanje z zasebnostjo v pogovornih vmesnikih:
Postopno razkritje zasebnosti, ki uvaja informacije v obvladljive segmente
Indikatorji zasebnosti okolja, ki uporabljajo subtilne zvočne ali vizualne namige, ki kažejo, kdaj sistemi poslušajo ali obdelujejo
Koreografija soglasja, ki oblikuje naravne zahteve za dovoljenja, ki ne motijo toka pogovora
Privzete nastavitve za ohranjanje zasebnosti, ki se začnejo z minimalnim zbiranjem podatkov in se razširijo le z izrecno odobritvijo uporabnika
Pozabljanje mehanizmov, zaradi katerih sta potek in brisanje podatkov sestavni del modela interakcije
Namen teh vzorcev načrtovanja je, da vidiki zasebnosti postanejo integrirani del pogovorne izkušnje in ne ločena plast zahtev glede skladnosti.
Najboljše organizacijske prakse
Organizacije, ki so vodilne na področju pogovorne umetne inteligence, ki spoštuje zasebnost, običajno izvajajo več ključnih praks:
Zagovorniki zasebnosti, vključeni v razvojne ekipe, ne le v pravne oddelke
Redne ocene tveganja zasebnosti v celotnem življenjskem ciklu razvoja
Uporabniško testiranje, osredotočeno na zasebnost, ki izrecno ocenjuje razumevanje in nadzor zasebnosti
Poročila o preglednosti, ki zagotavljajo vpogled v podatkovne prakse in vladne zahteve po informacijah
Zunanje revizije zasebnosti, ki potrjujejo, da se dejanske prakse ujemajo z navedenimi politikami
Programi nagrad za napake v zasebnosti, ki spodbujajo odkrivanje ranljivosti zasebnosti
Ti organizacijski pristopi zagotavljajo, da ostajajo vidiki zasebnosti osrednji v celotnem razvoju izdelka, namesto da postanejo naknadna misel med pravnim pregledom.
Za razvijalce in podjetja, ki delajo v tem prostoru, te nastajajoče rešitve zagotavljajo dragoceno usmeritev za ustvarjanje pogovorne umetne inteligence, ki spoštuje zasebnost in hkrati zagotavlja prepričljive uporabniške izkušnje. Čeprav noben posamezen pristop ne reši vseh izzivov glede zasebnosti, lahko premišljena kombinacija tehničnih, oblikovalskih in organizacijskih praks bistveno izboljša rezultate glede zasebnosti.
Prihodnost zasebnosti v pogovorni AI
As we look ahead, several trends are likely to shape the evolving relationship between conversational AI and privacy.
From Centralized to Distributed Intelligence
The architecture of conversational AI systems is increasingly shifting from fully cloud-based approaches toward more distributed models:
Personal AI agents that run primarily on user devices, maintaining private knowledge bases about individual preferences and patterns
Hybrid processing systems that handle sensitive functions locally while leveraging cloud resources for compute-intensive tasks
User-controlled cloud instances where individuals own their data and the processing resources that operate on it
Decentralized learning approaches that improve AI systems without centralizing user data
These architectural shifts fundamentally change the privacy equation by keeping more personal data under user control rather than aggregating it in centralized corporate repositories.
Evolving Regulatory Approaches
Privacy regulation for conversational AI continues to develop, with several emerging trends:
AI-specific regulations that address unique challenges beyond general data protection frameworks
Global convergence around core privacy principles despite regional variations in specific requirements
Certification programs providing standardized ways to verify privacy protections
Algorithmic transparency requirements mandating explanation of how AI systems use personal data
These regulatory developments will likely establish clearer boundaries for conversational AI while potentially creating more predictable compliance environments for developers.
Shifting User Expectations
User attitudes toward privacy in conversational contexts are evolving as experience with these technologies grows:
Increasing sophistication about privacy trade-offs and the value of personal data
Greater demand for transparency about how conversational data improves AI systems
Rising expectations for granular control over different types of personal information
Growing concern about emotional and psychological profiles created through conversation analysis
These evolving attitudes will shape market demand for privacy features and potentially reward companies that offer stronger protections.
Ethical AI and Value Alignment
Beyond legal compliance, conversational AI is increasingly evaluated against broader ethical frameworks:
Value alignment ensuring AI systems respect user privacy values even when not legally required
Distributive justice addressing privacy disparities across different user groups
Intergenerational equity considering long-term privacy implications of data collected today
Collective privacy interests recognizing that individual privacy choices affect broader communities
These ethical considerations extend privacy discussions beyond individual rights to consider societal impacts and collective interests that may not be fully addressed by individual choice frameworks.
Privacy as Competitive Advantage
As privacy awareness grows, market dynamics around conversational AI are evolving:
Privacy-focused alternatives gaining traction against data-intensive incumbents
Premium positioning for high-privacy options in various market segments
Increased investment in privacy-enhancing technologies to enable differentiation
Enterprise buyers prioritizing privacy features in procurement decisions
These market forces create economic incentives for privacy innovation beyond regulatory compliance, potentially accelerating development of privacy-respecting alternatives.
The future of privacy in conversational AI will be shaped by the interplay of these technological, regulatory, social, and market forces. While perfect privacy solutions remain elusive, the direction of development suggests increasing options for users who seek more privacy-respecting conversational experiences.
For developers, businesses, and users engaged with these systems, staying informed about emerging approaches and actively participating in shaping privacy norms and expectations will be essential as conversational AI becomes an increasingly central part of our digital lives.
Conclusion: Toward Responsible Conversational AI
As conversational AI continues its rapid evolution and integration into our daily lives, the privacy challenges we've explored take on increasing urgency. These systems promise tremendous benefits—more natural human-computer interaction, accessibility for those who struggle with traditional interfaces, and assistance that adapts to individual needs. Realizing these benefits while protecting fundamental privacy rights requires thoughtful navigation of complex trade-offs.
The path forward isn't about choosing between functionality and privacy as mutually exclusive options. Rather, it involves creative problem-solving to design systems that deliver valuable capabilities while respecting privacy boundaries. This requires technical innovation, thoughtful design, organizational commitment, and appropriate regulation working in concert.
For developers, the challenge lies in creating systems that collect only necessary data, process it with appropriate safeguards, and provide meaningful transparency and control. For businesses, it means recognizing privacy as a core value proposition rather than a compliance burden. For users, it involves becoming more informed about privacy implications and expressing preferences through both settings choices and market decisions.
Perhaps most importantly, advancing privacy-respecting conversational AI requires ongoing dialogue between all stakeholders—technologists, businesses, policymakers, privacy advocates, and users themselves. These conversations need to address not just what's technically possible or legally required, but what kind of relationship we want with the increasingly intelligent systems that mediate our digital experiences.
The decisions we make today about conversational AI privacy will shape not just current products but the trajectory of human-AI interaction for years to come. By approaching these challenges thoughtfully, we can create conversational systems that earn trust through respect for privacy rather than demanding trust despite privacy concerns.
The most successful conversational AI won't be the systems that collect the most data or even those that provide the most functionality, but those that strike a thoughtful balance—delivering valuable assistance while respecting the fundamental human need for privacy and control over personal information. Achieving this balance is not just good ethics; it's the foundation for sustainable, beneficial AI that serves human flourishing.
From Centralized to Distributed Intelligence
The architecture of conversational AI systems is increasingly shifting from fully cloud-based approaches toward more distributed models:
Personal AI agents that run primarily on user devices, maintaining private knowledge bases about individual preferences and patterns
Hybrid processing systems that handle sensitive functions locally while leveraging cloud resources for compute-intensive tasks
User-controlled cloud instances where individuals own their data and the processing resources that operate on it
Decentralized learning approaches that improve AI systems without centralizing user data
These architectural shifts fundamentally change the privacy equation by keeping more personal data under user control rather than aggregating it in centralized corporate repositories.
Evolving Regulatory Approaches
Privacy regulation for conversational AI continues to develop, with several emerging trends:
AI-specific regulations that address unique challenges beyond general data protection frameworks
Global convergence around core privacy principles despite regional variations in specific requirements
Certification programs providing standardized ways to verify privacy protections
Algorithmic transparency requirements mandating explanation of how AI systems use personal data
These regulatory developments will likely establish clearer boundaries for conversational AI while potentially creating more predictable compliance environments for developers.
Shifting User Expectations
User attitudes toward privacy in conversational contexts are evolving as experience with these technologies grows:
Increasing sophistication about privacy trade-offs and the value of personal data
Greater demand for transparency about how conversational data improves AI systems
Rising expectations for granular control over different types of personal information
Growing concern about emotional and psychological profiles created through conversation analysis
These evolving attitudes will shape market demand for privacy features and potentially reward companies that offer stronger protections.
Ethical AI and Value Alignment
Beyond legal compliance, conversational AI is increasingly evaluated against broader ethical frameworks:
Value alignment ensuring AI systems respect user privacy values even when not legally required
Distributive justice addressing privacy disparities across different user groups
Intergenerational equity considering long-term privacy implications of data collected today
Collective privacy interests recognizing that individual privacy choices affect broader communities
These ethical considerations extend privacy discussions beyond individual rights to consider societal impacts and collective interests that may not be fully addressed by individual choice frameworks.
Privacy as Competitive Advantage
As privacy awareness grows, market dynamics around conversational AI are evolving:
Privacy-focused alternatives gaining traction against data-intensive incumbents
Premium positioning for high-privacy options in various market segments
Increased investment in privacy-enhancing technologies to enable differentiation
Enterprise buyers prioritizing privacy features in procurement decisions
These market forces create economic incentives for privacy innovation beyond regulatory compliance, potentially accelerating development of privacy-respecting alternatives.
The future of privacy in conversational AI will be shaped by the interplay of these technological, regulatory, social, and market forces. While perfect privacy solutions remain elusive, the direction of development suggests increasing options for users who seek more privacy-respecting conversational experiences.
For developers, businesses, and users engaged with these systems, staying informed about emerging approaches and actively participating in shaping privacy norms and expectations will be essential as conversational AI becomes an increasingly central part of our digital lives.
Conclusion: Toward Responsible Conversational AI
As conversational AI continues its rapid evolution and integration into our daily lives, the privacy challenges we've explored take on increasing urgency. These systems promise tremendous benefits—more natural human-computer interaction, accessibility for those who struggle with traditional interfaces, and assistance that adapts to individual needs. Realizing these benefits while protecting fundamental privacy rights requires thoughtful navigation of complex trade-offs.
The path forward isn't about choosing between functionality and privacy as mutually exclusive options. Rather, it involves creative problem-solving to design systems that deliver valuable capabilities while respecting privacy boundaries. This requires technical innovation, thoughtful design, organizational commitment, and appropriate regulation working in concert.
For developers, the challenge lies in creating systems that collect only necessary data, process it with appropriate safeguards, and provide meaningful transparency and control. For businesses, it means recognizing privacy as a core value proposition rather than a compliance burden. For users, it involves becoming more informed about privacy implications and expressing preferences through both settings choices and market decisions.
Perhaps most importantly, advancing privacy-respecting conversational AI requires ongoing dialogue between all stakeholders—technologists, businesses, policymakers, privacy advocates, and users themselves. These conversations need to address not just what's technically possible or legally required, but what kind of relationship we want with the increasingly intelligent systems that mediate our digital experiences.
The decisions we make today about conversational AI privacy will shape not just current products but the trajectory of human-AI interaction for years to come. By approaching these challenges thoughtfully, we can create conversational systems that earn trust through respect for privacy rather than demanding trust despite privacy concerns.
The most successful conversational AI won't be the systems that collect the most data or even those that provide the most functionality, but those that strike a thoughtful balance—delivering valuable assistance while respecting the fundamental human need for privacy and control over personal information. Achieving this balance is not just good ethics; it's the foundation for sustainable, beneficial AI that serves human flourishing.